To appear at 2026 IEEE 22nd International Conference on Automation Science and Engineering (CASE), August 2026
LG Electronics AI Lab
TL;DR
이 연구는 건조기 내부 영상에서 사람이 판단할 수 있는 세탁물 모션 품질을 센서 기반 reward model로 전이하고, 이를 강화학습에 활용하여 실제 제품 센서만으로 동작 가능한 drum-speed 제어 정책을 학습하는 방법입니다.
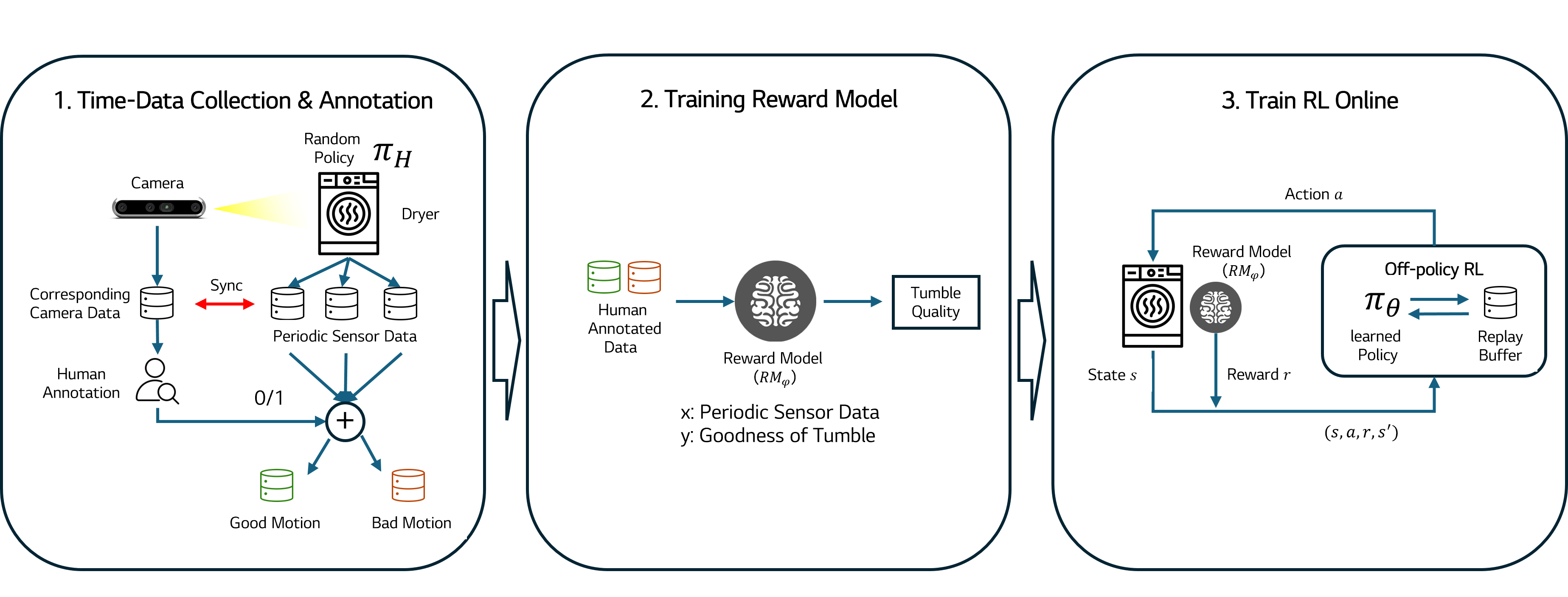
Overview
Problem
건조 효율을 높이기 위해서는 세탁물이 drum 내부에서 cataracting motion을 유지해야 하지만, 실제 제품에서 사용할 수 있는 motor current, RPM 계열 센서만으로 내부 모션 상태를 직접 관측하기는 어렵습니다.
Approach
개발 단계에서 센서 데이터와 내부 영상을 동기화해 수집하고, 영상 기반 label 또는 pairwise preference를 이용해 sensor-only reward model을 학습합니다. 이후 해당 reward model을 고정한 상태에서 SAC 기반 drum-speed 제어 정책을 학습합니다.
Outcome
5개의 load composition에서 expert-designed baseline 대비 normalized moisture-removal metric이 평균 2.04%, 최대 2.86% 개선되었습니다.
Motion Labels
Bad Motion: Wall-Following

세탁물이 drum 벽면을 따라 붙어 움직이면 공기와 접촉하는 유효 표면적이 줄어듭니다.
Bad Motion: Rolling

Load가 drum 하단에서 rolling 형태로 움직이면 목표로 하는 falling motion에 도달하지 못합니다.
Good Motion: Tumbling

목표 motion은 세탁물 표면을 heated airflow에 더 고르게 노출시켜 건조 효율을 높입니다.
Method
실제 건조기에서 onboard sensor sequence와 drum 내부 영상을 동기화해 수집합니다.
→
영상 label 또는 preference를 이용해 sensor history만 입력으로 받는 LSTM 기반 reward model을 학습합니다.
→
고정된 reward model이 제공하는 reward를 사용해 drum speed를 조절하는 SAC controller를 학습합니다.
- Drum speed를 동작 범위에서 sweep하며 센서 데이터와 내부 영상을 동시에 기록합니다.
- 영상 clip에 대해 desirable/undesirable tumble motion label을 부여하거나, 두 clip 간 상대적인 motion quality preference를 표시합니다.
- Annotation을 sensor window와 정렬하고 sensor-only reward model을 학습합니다.
- 학습된 reward를 이용해 Soft Actor-Critic 기반 incremental drum-speed controller를 학습합니다.
- 최종 controller는 영상 없이 제품 센서 stream만으로 동작합니다.
Motion Supervision
핵심은 영상을 개발 단계의 supervision으로만 사용하는 것입니다. 사람이 영상으로 판단할 수 있는 tumble quality를 sensor history에서 scalar motion quality를 예측하는 reward model로 증류하기 때문에, 최종 제어기는 실제 제품의 센서 제약 안에서 동작할 수 있습니다.
5 평가한 load composition
2.04% 평균 상대 성능 개선
2.86% 최대 상대 성능 개선
Development Setup


Sensor stream과 내부 motion 관측값을 동기화해 수집하고, 학습된 controller를 평가하기 위해 사용한 실제 household dryer setup입니다.
Results
Moisture-Removal Performance
제안한 controller는 5개 평가 load 모두에서 normalized moisture-removal metric을 개선했습니다. 평균 metric은 0.6129에서 0.6261로 증가했으며, load별 평균 상대 개선율은 2.04%입니다.
Load Coverage
실험은 3 kg/5 kg mixed-fabric load, cotton-to-polyester 비율이 다른 조합, 3 kg towel-heavy load를 포함합니다.
Preference Reward Check
Towel-heavy load에서는 preference-based reward model도 검증했습니다. Binary motion label의 전반적인 추세와 유사하게 reward가 형성되었고, 성능은 baseline 대비 2.10% 개선되었습니다.
Deployment Constraint
영상은 개발 단계에서 annotation을 만들기 위해서만 사용합니다. RL 학습과 deployment 단계에서는 reward model과 controller 모두 onboard sensor sequence만 사용합니다.
Videos
건조기 tumble-motion control supplementary video.
Citation
@misc{lee2026sensorRewardDryer,
title = {Sensor-Based Reward Learning from Video Labels for Tumble Motion Control in a Household Dryer},
author = {Lee, Jinwoo and Kang, Chanseok and Bae, Guntae},
note = {To appear at 2026 IEEE 22nd International Conference on Automation Science and Engineering (CASE)},
year = {2026}
}