Chan’s Research Note
English
한국어
Home
About
Blog
Publications
Activities
Categories
All
(15)
CS224R
(7)
CS330
(5)
GenAI
(1)
Lecture
(12)
Life
(2)
math
(1)
numpy
(1)
python
(1)
Blog
A collection of articles on AI research, implementation, and insights.
Model-Based RL
Lecture
CS224R
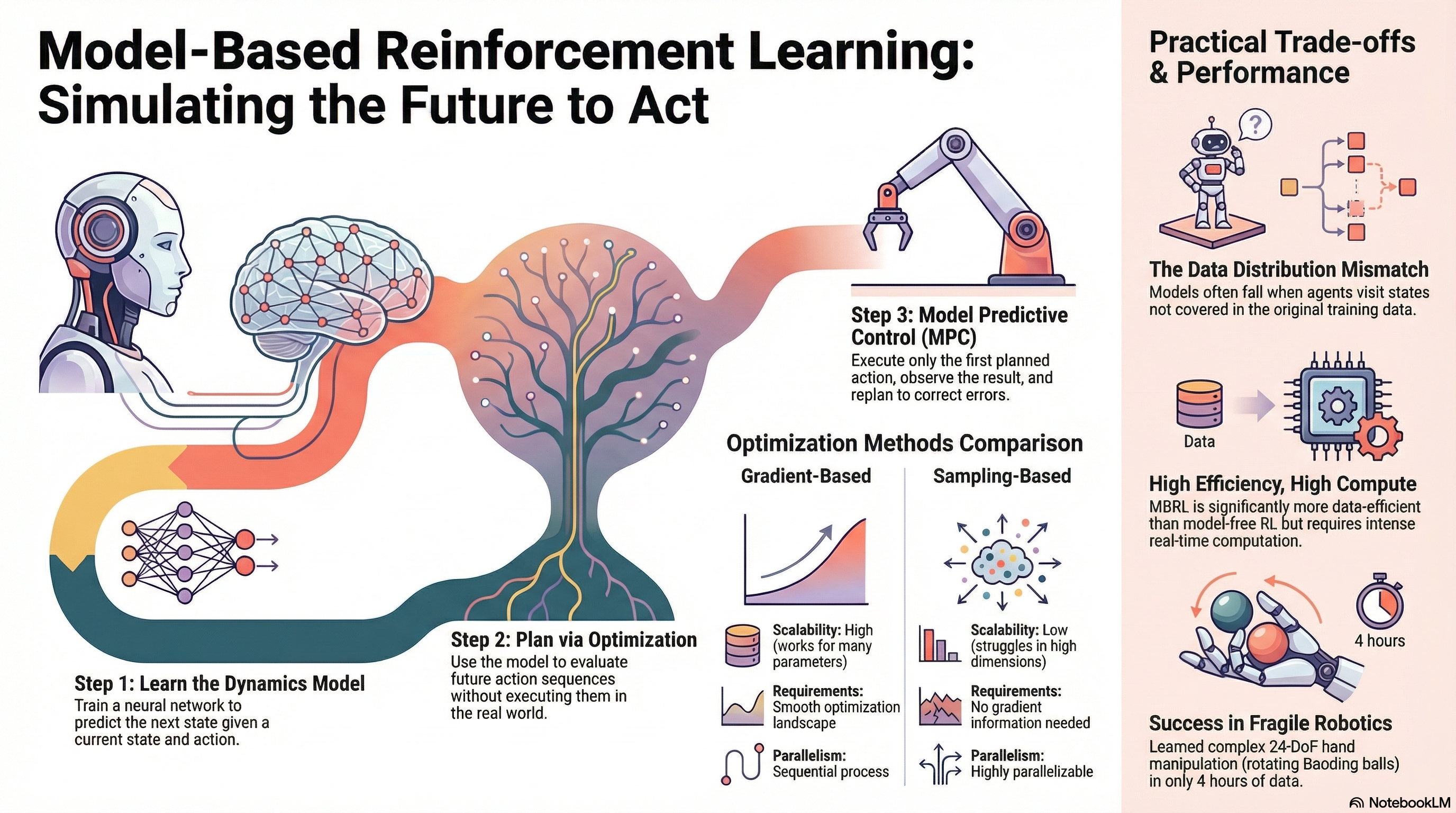
Summary of lecture CS224R (2025) Lecture 11. Model-Based RL
Mar 30, 2026
Chanseok Kang
RL for LLMs - Preference Optimization
Lecture
CS224R
Summary of lecture CS224R (2025) Lecture 9. RL for LLMs:Preference Optimization
Mar 20, 2026
Chanseok Kang
Reward Learning
Lecture
CS224R
Summary of lecture CS224R (2025) Lecture 8. Reward Learning
Mar 11, 2026
Chanseok Kang
Offline RL
Lecture
CS224R
Summary of lecture CS224R (2025) Lecture 7. Offline RL
Feb 25, 2026
Chanseok Kang
Non Parametric Few-Shot Learning
Lecture
CS330
Summary of lecture CS330 (2022) Lecture 6. Non Parametric Few-Shot Learning
Feb 23, 2026
Chanseok Kang
Q-Learning
Lecture
CS224R
Summary of lecture CS224R (2025) Lecture 6. Q-Learning
Feb 13, 2026
Chanseok Kang
Optimization-Based Meta-Learning
Lecture
CS330
Summary of lecture CS330 (2022) Lecture 5. Optimization-Based Meta-Learning
Feb 10, 2026
Chanseok Kang
Off-Policy Actor-Critic Methods
Lecture
CS224R
Summary of lecture CS224R (2025) Lecture 5. Off-Policy Actor-Critic Methods
Feb 4, 2026
Chanseok Kang
Black-Box Meta-Learning & In-Context Learning
Lecture
CS330
Summary of lecture CS330 (2022) Lecture 4. Black-Box Meta-Learning & In-Context Learning
Feb 2, 2026
Chanseok Kang
Actor-Critic Methods
Lecture
CS224R
Summary of lecture CS224R (2025) Lecture 4. Actor-Critic Methods
Jan 30, 2026
Chanseok Kang
Transfer Learning & Fine-tuning
Lecture
CS330
Summary of lecture CS330 (2022) Lecture 3. Transfer learning & Fine-tuning
Jan 26, 2026
Chanseok Kang
Multi-task learning
Lecture
CS330
Summary of lecture CS330 (2022) Lecture 2. Multi-task learning
Jan 20, 2026
Chanseok Kang
retrospective of 2025
Life
Reflections on 2025 - Achievements, Regrets, and Resolutions
Dec 29, 2025
Chanseok Kang
Experiences I had while doing Vibe Coding
GenAI
Life
My experience using ChatGPT and Gemini Code Assist (Agent Mode)
Jul 31, 2025
Chanseok Kang
Taylor Expansion
python
numpy
math
Applying Taylor Expansion in various functions.
Jul 28, 2025
Chanseok Kang
No matching items