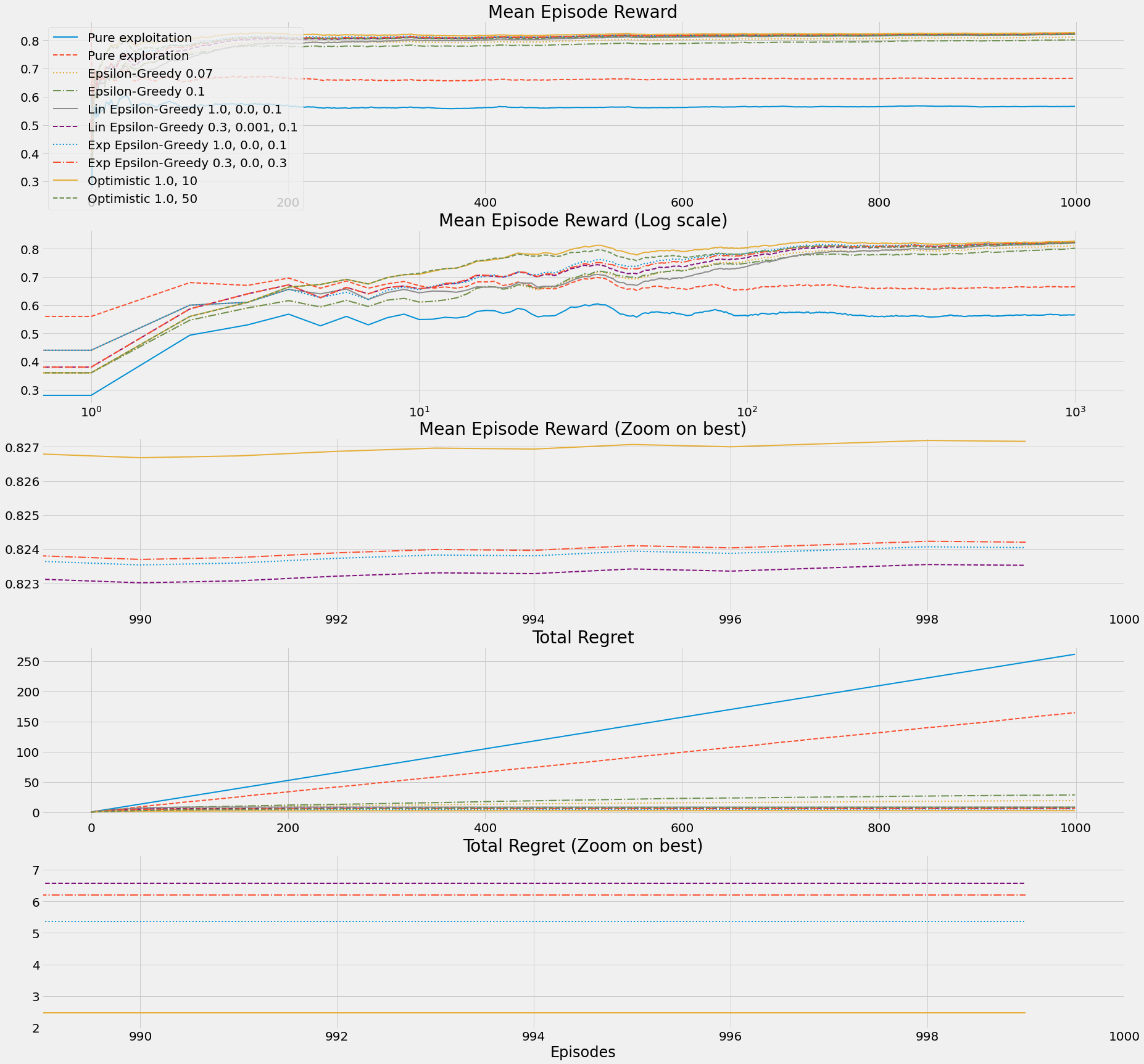
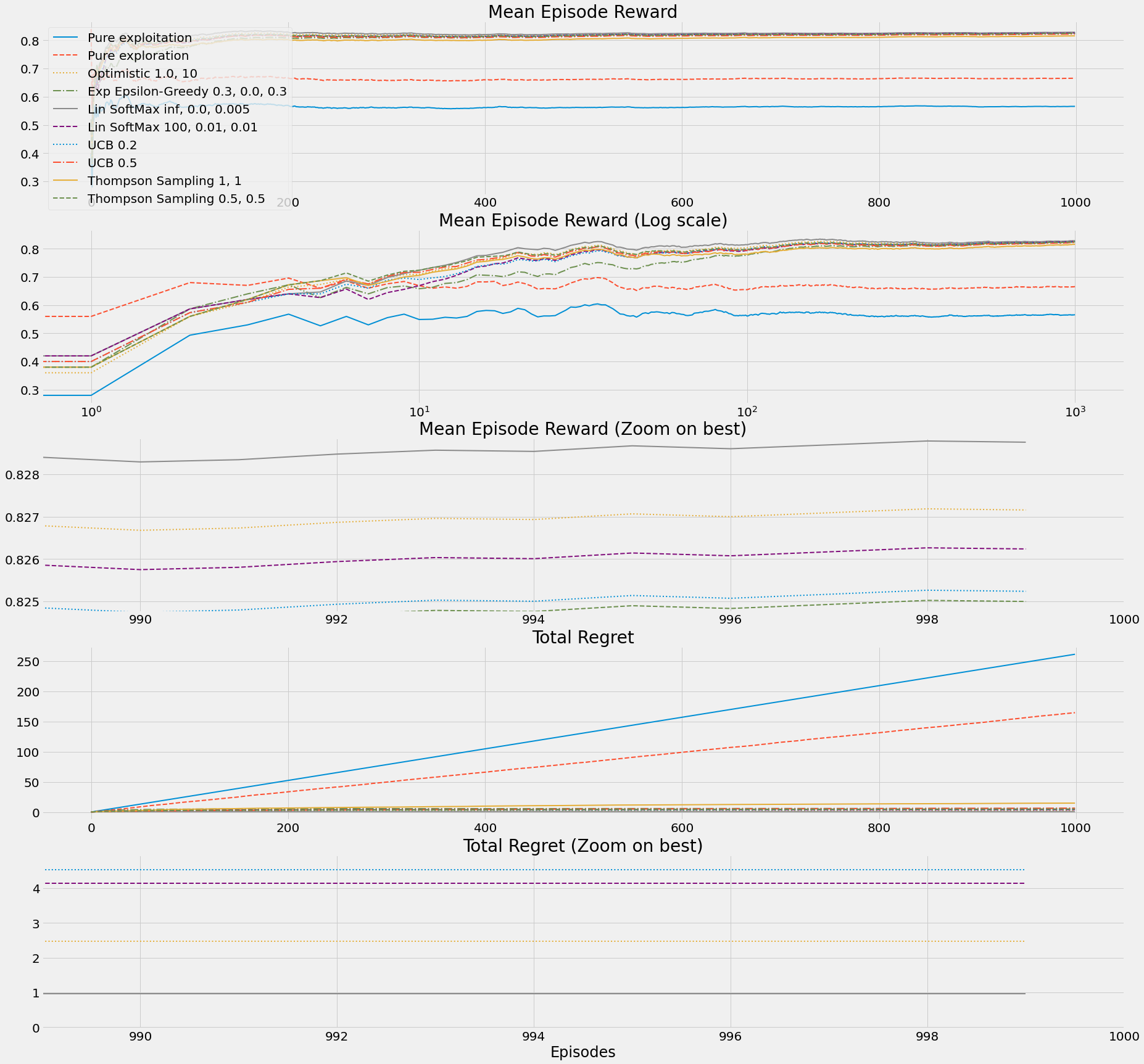
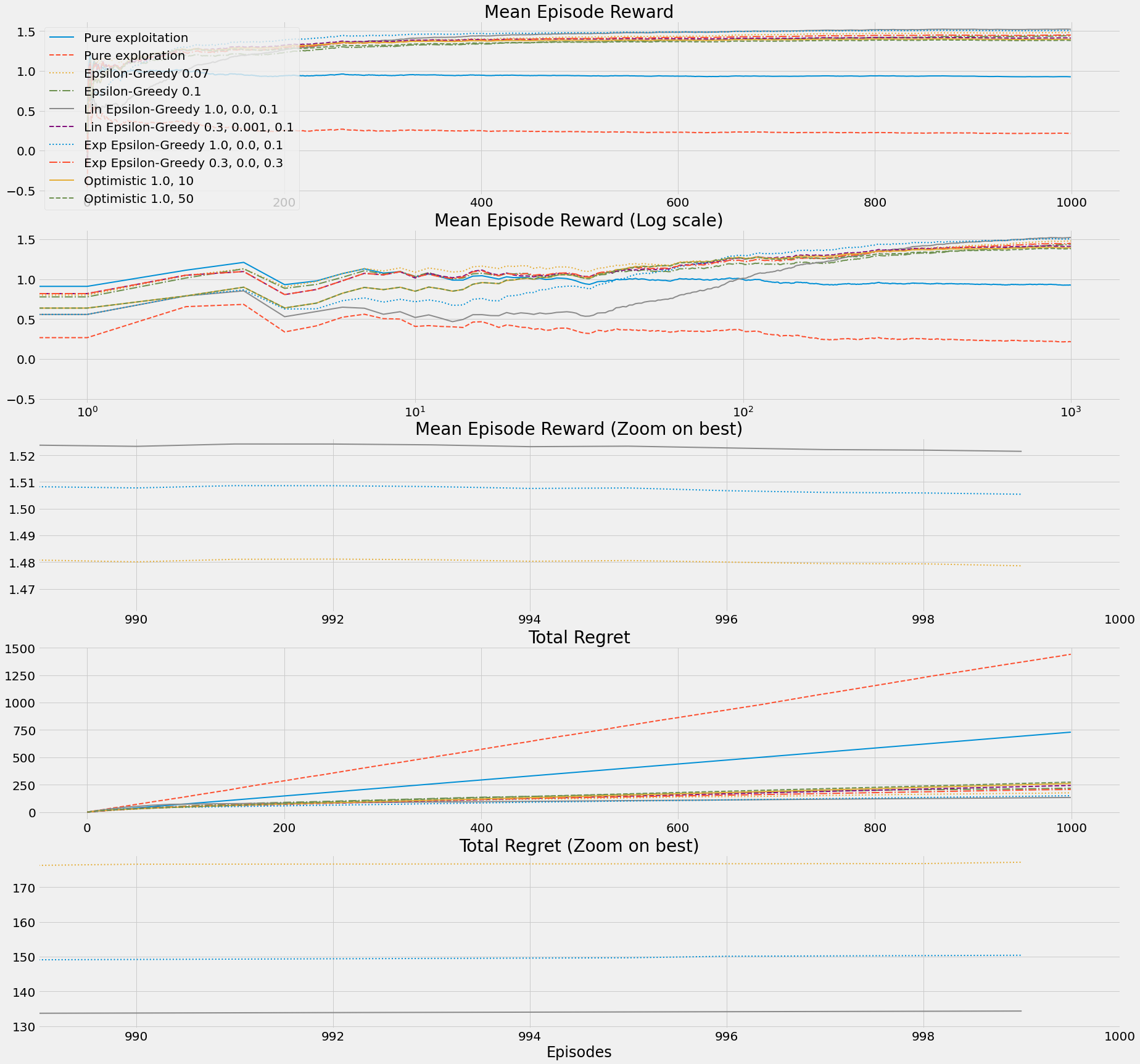
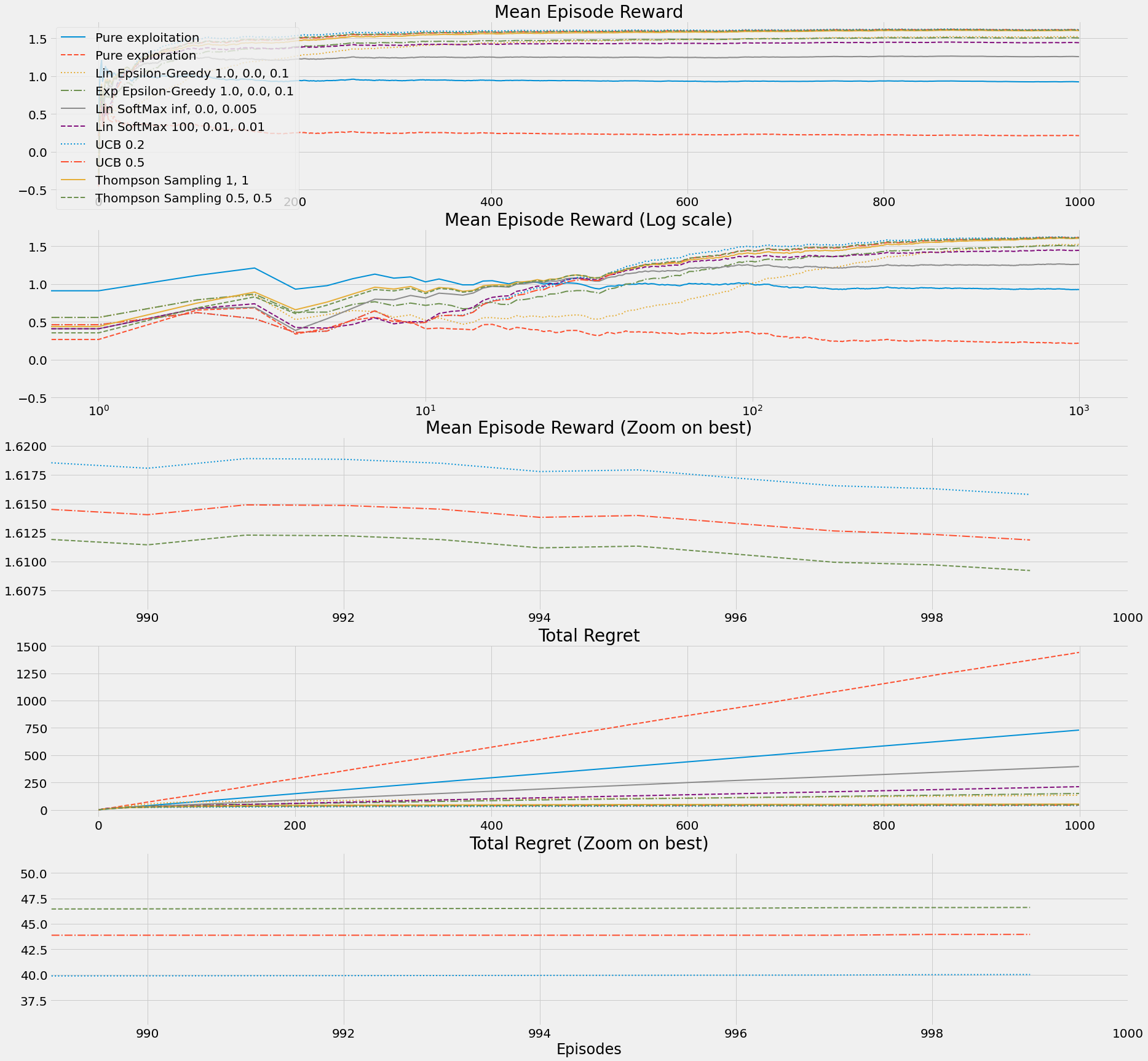
def b10_run_simple_strategies_experiment(env_name='BanditTenArmedGaussian-v0'):
results = {}
experiments = [
# baseline strategies
lambda env: pure_exploitation(env),
lambda env: pure_exploration(env),
# epsilon greedy
lambda env: epsilon_greedy(env, epsilon=0.07),
lambda env: epsilon_greedy(env, epsilon=0.1),
# epsilon greedy linearly decaying
lambda env: lin_dec_epsilon_greedy(env,
init_epsilon=1.0,
min_epsilon=0.0,
decay_ratio=0.1),
lambda env: lin_dec_epsilon_greedy(env,
init_epsilon=0.3,
min_epsilon=0.001,
decay_ratio=0.1),
# epsilon greedy exponentially decaying
lambda env: exp_dec_epsilon_greedy(env,
init_epsilon=1.0,
min_epsilon=0.0,
decay_ratio=0.1),
lambda env: exp_dec_epsilon_greedy(env,
init_epsilon=0.3,
min_epsilon=0.0,
decay_ratio=0.3),
# optimistic
lambda env: optimistic_initialization(env,
optimistic_estimate=1.0,
initial_count=10),
lambda env: optimistic_initialization(env,
optimistic_estimate=1.0,
initial_count=50),
]
for env_seed in tqdm(SEEDS, desc='All experiments'):
env = gym.make(env_name, seed=env_seed) ; env.reset()
r_dist = np.array(env.env.r_dist)[:,0]
true_Q = np.array(env.env.p_dist * r_dist)
opt_V = np.max(true_Q)
for seed in tqdm(SEEDS, desc='All environments', leave=False):
for experiment in tqdm(experiments,
desc='Experiments with seed {}'.format(seed),
leave=False):
env.seed(seed) ; np.random.seed(seed) ; random.seed(seed)
name, Re, Qe, Ae = experiment(env)
Ae = np.expand_dims(Ae, -1)
episode_mean_rew = np.cumsum(Re) / (np.arange(len(Re)) + 1)
Q_selected = np.take_along_axis(
np.tile(true_Q, Ae.shape), Ae, axis=1).squeeze()
regret = opt_V - Q_selected
cum_regret = np.cumsum(regret)
if name not in results.keys(): results[name] = {}
if 'Re' not in results[name].keys(): results[name]['Re'] = []
if 'Qe' not in results[name].keys(): results[name]['Qe'] = []
if 'Ae' not in results[name].keys(): results[name]['Ae'] = []
if 'cum_regret' not in results[name].keys():
results[name]['cum_regret'] = []
if 'episode_mean_rew' not in results[name].keys():
results[name]['episode_mean_rew'] = []
results[name]['Re'].append(Re)
results[name]['Qe'].append(Qe)
results[name]['Ae'].append(Ae)
results[name]['cum_regret'].append(cum_regret)
results[name]['episode_mean_rew'].append(episode_mean_rew)
return results
b10_results_s = b10_run_simple_strategies_experiment()