
읽고 나면 진짜 쉬워지는 자료 구조
Book
Data Structure



Actor-Critic Design Decisions
LectureReview
ReinforcementLearning
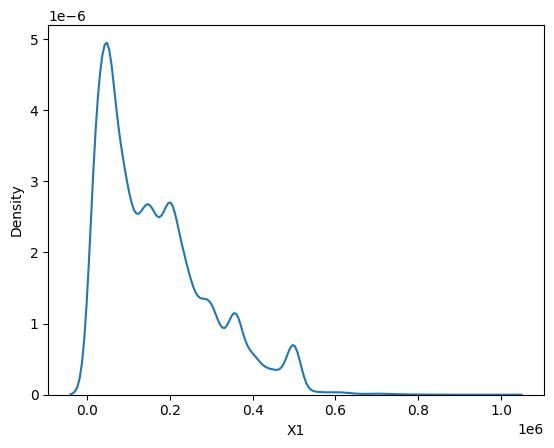
Pearson Correlation
Python
KAIST
Statistics
From Evaluation to Actor Critic
LectureReview
ReinforcementLearning
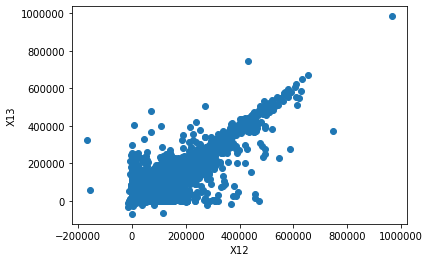
Covariance Matrix
Python
KAIST
Statistics
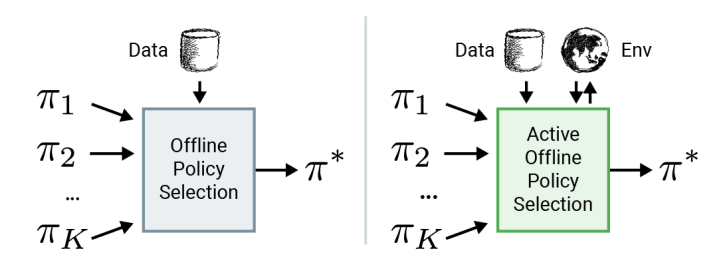
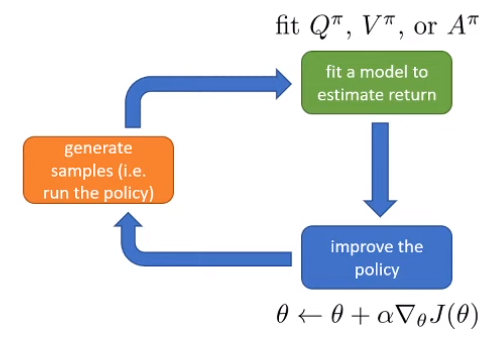
Actor-Critic Algorithms
LectureReview
ReinforcementLearning
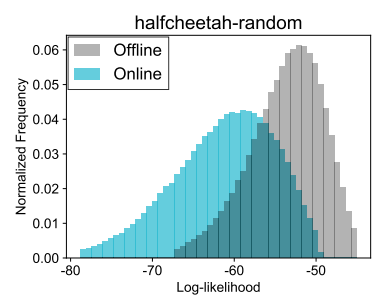
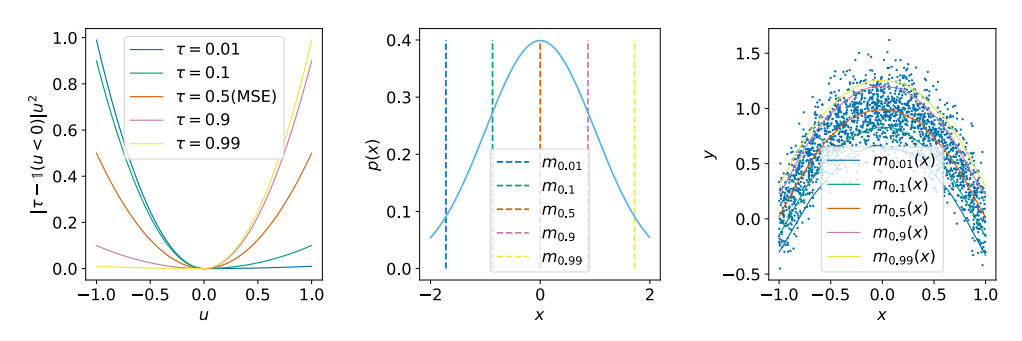
Offline Reinforcement Learning with Implicit Q-Learning
PaperReview
ReinforcementLearning
No matching items