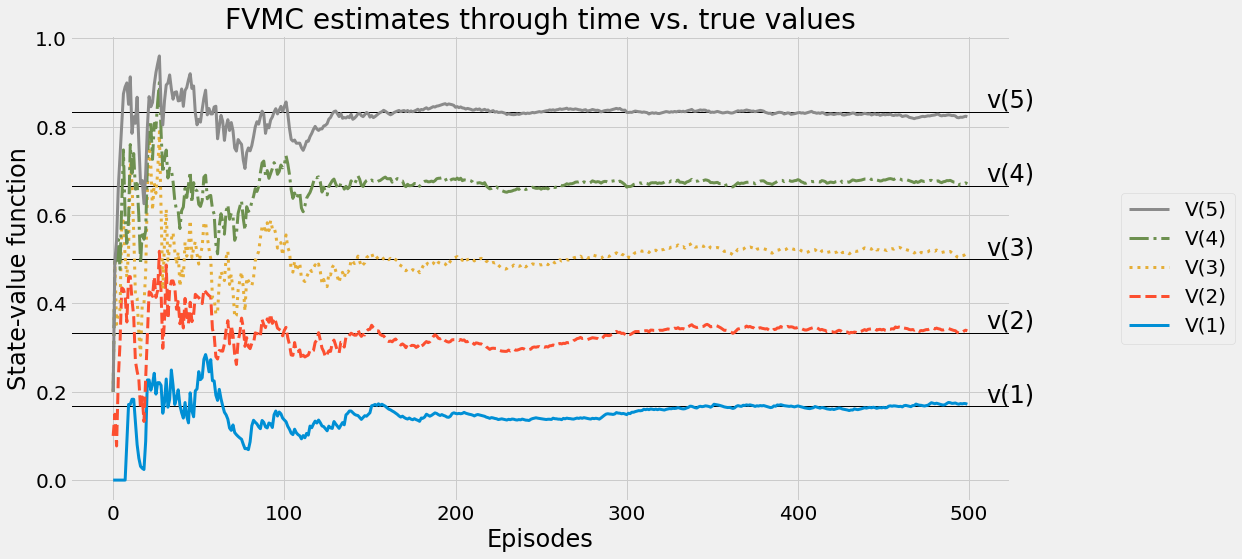
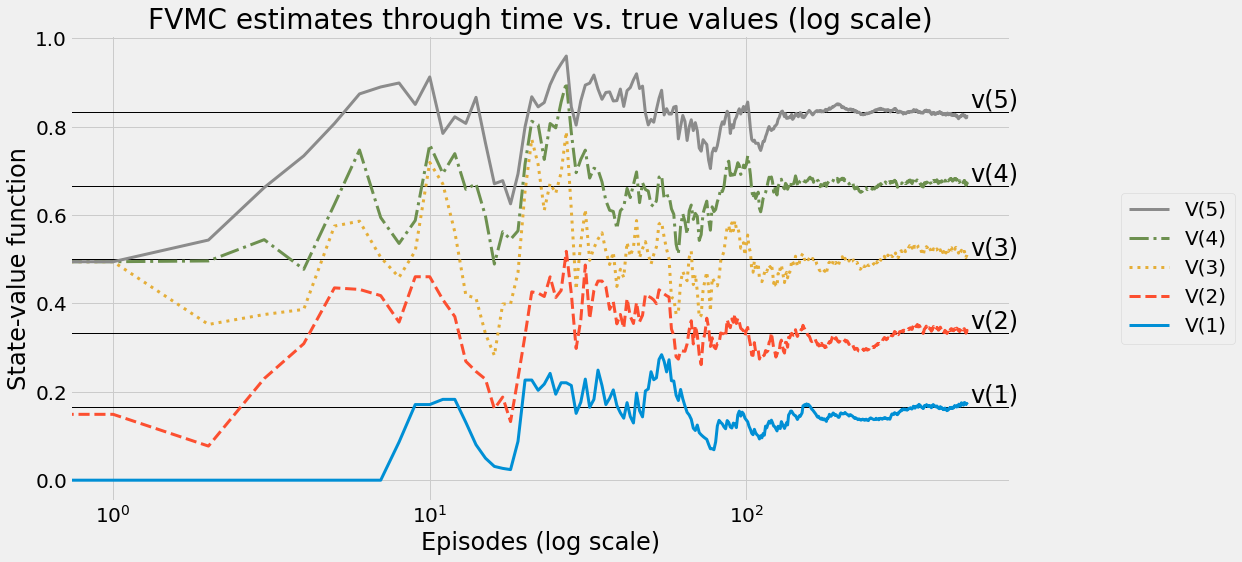
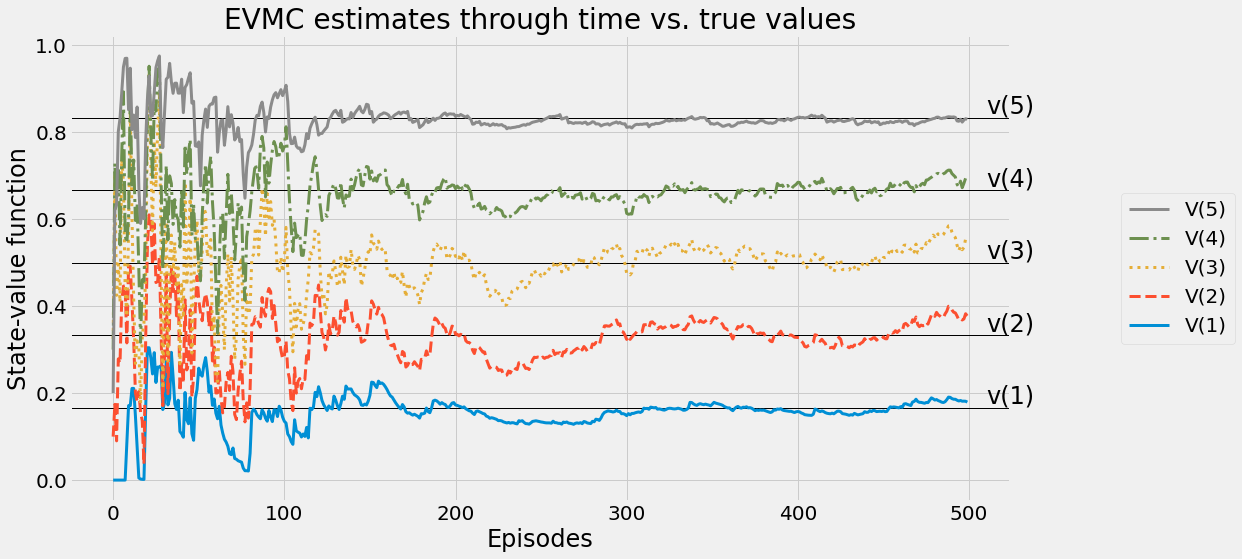
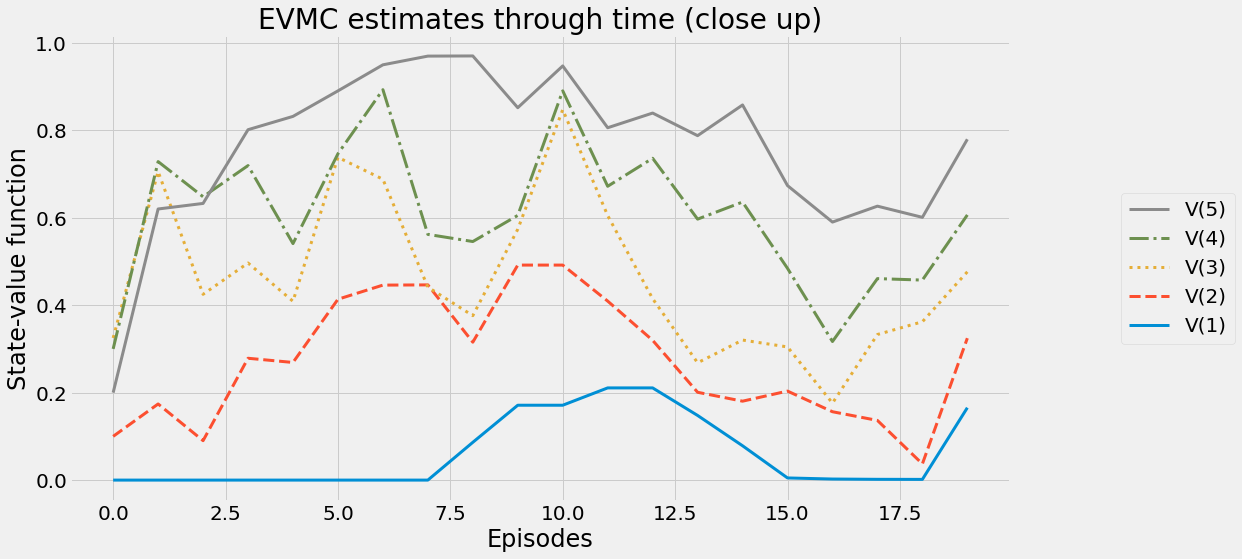
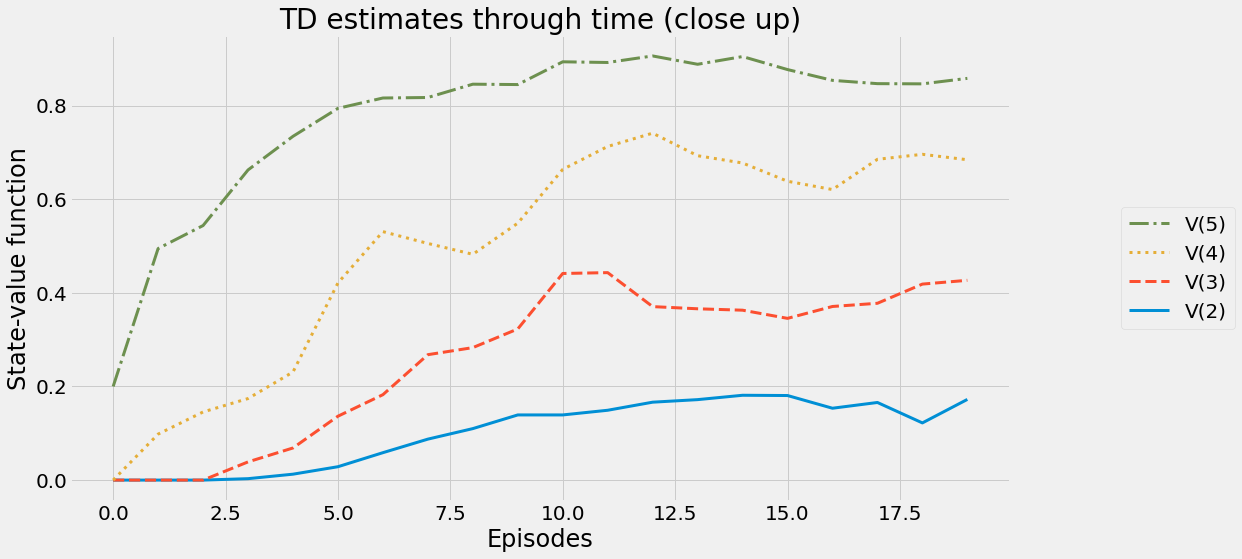
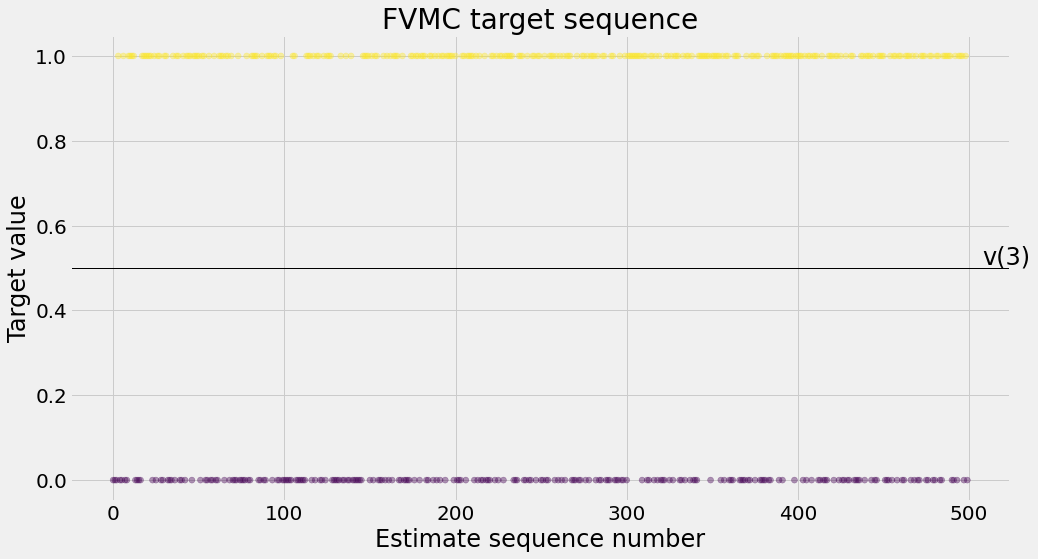
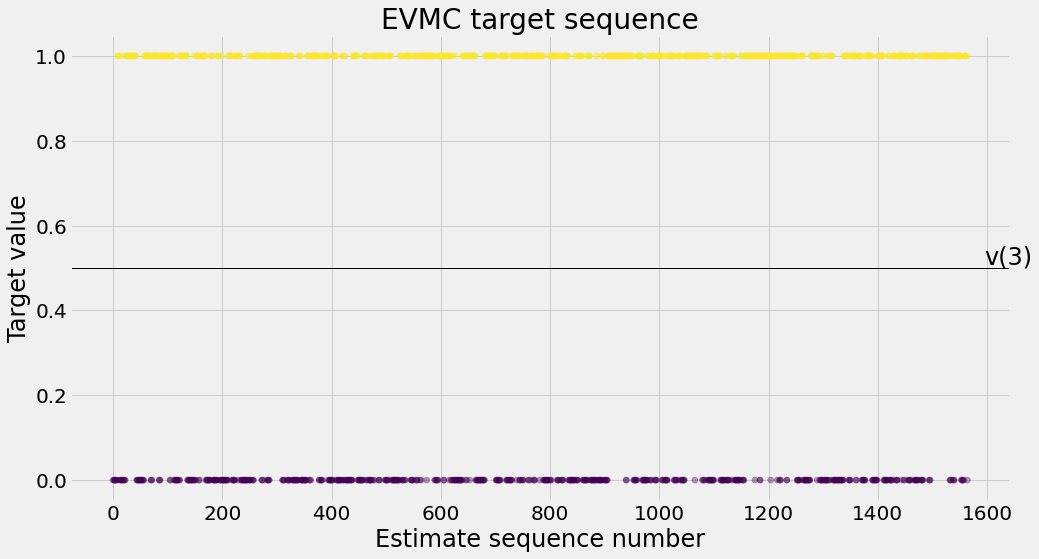
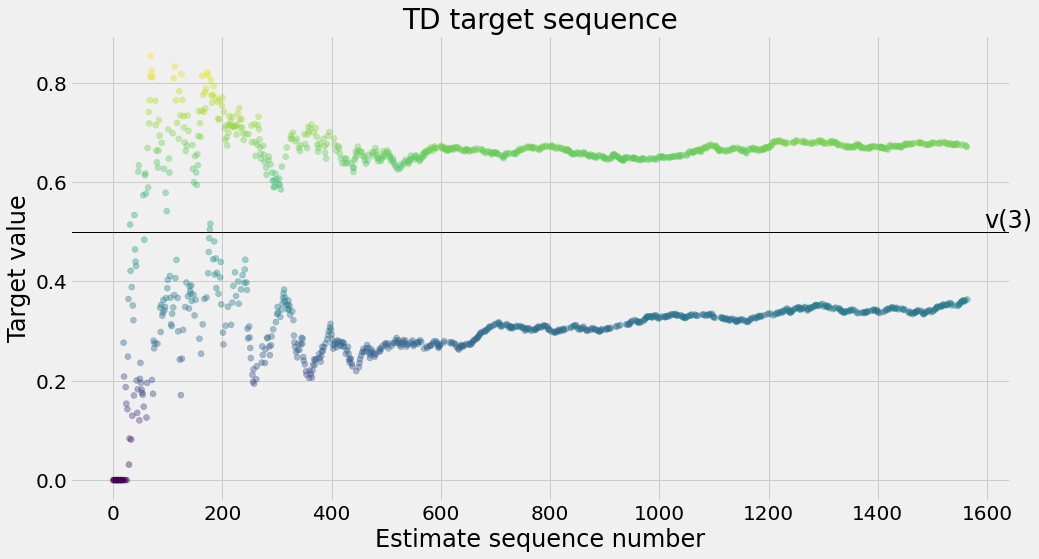
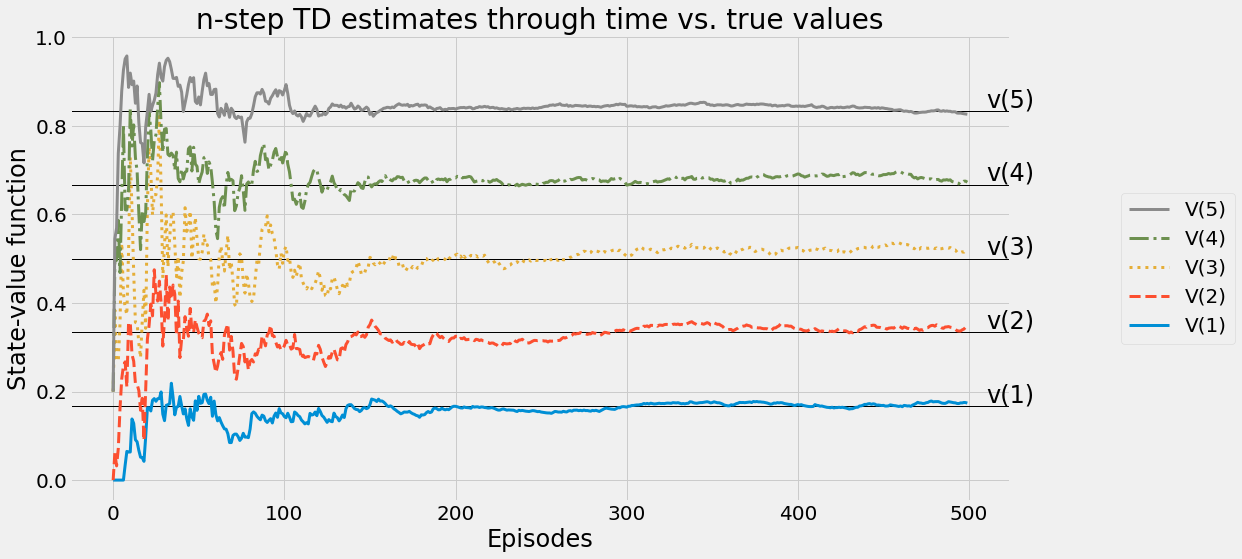
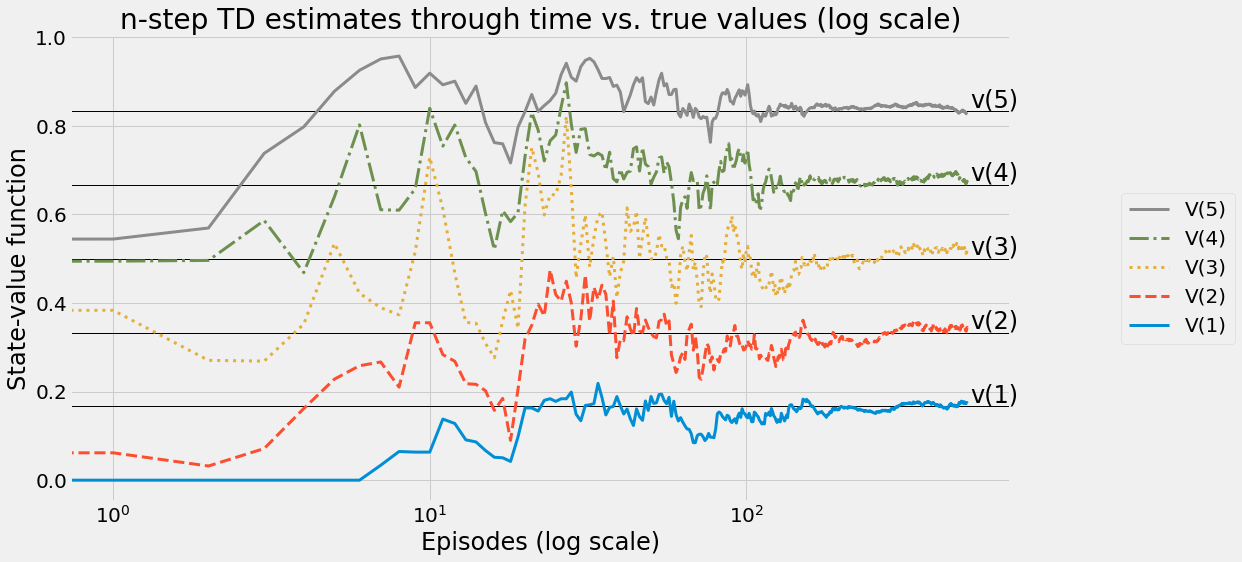
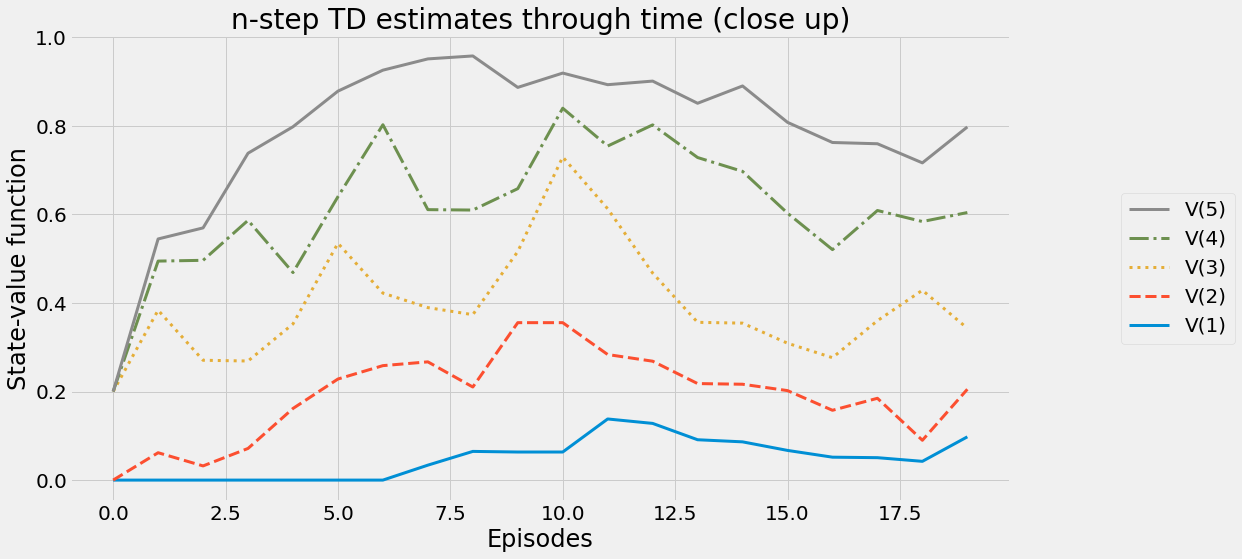
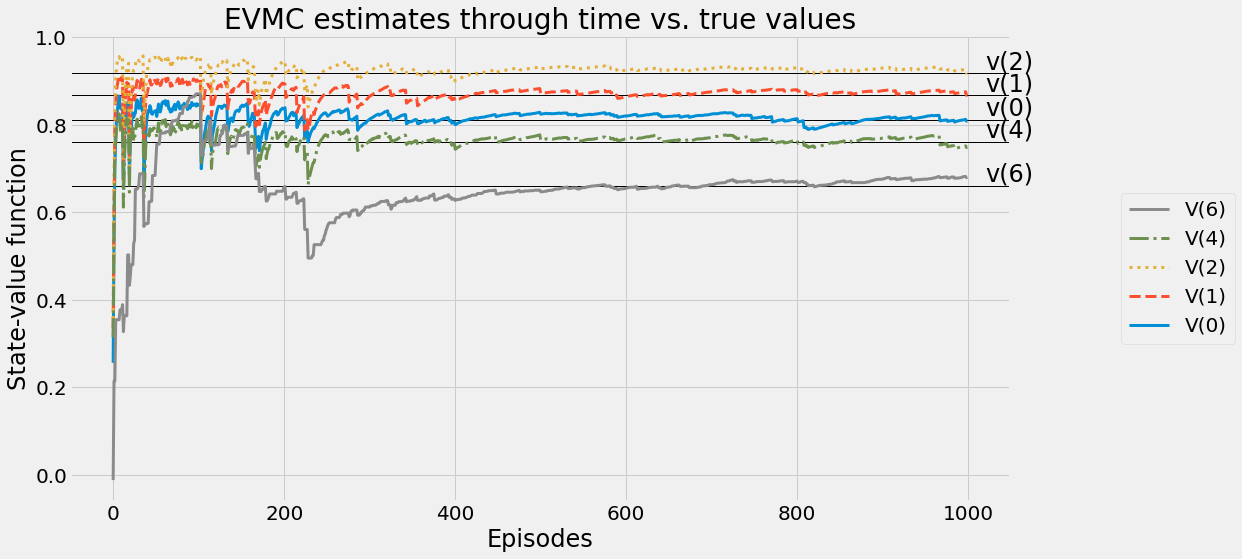
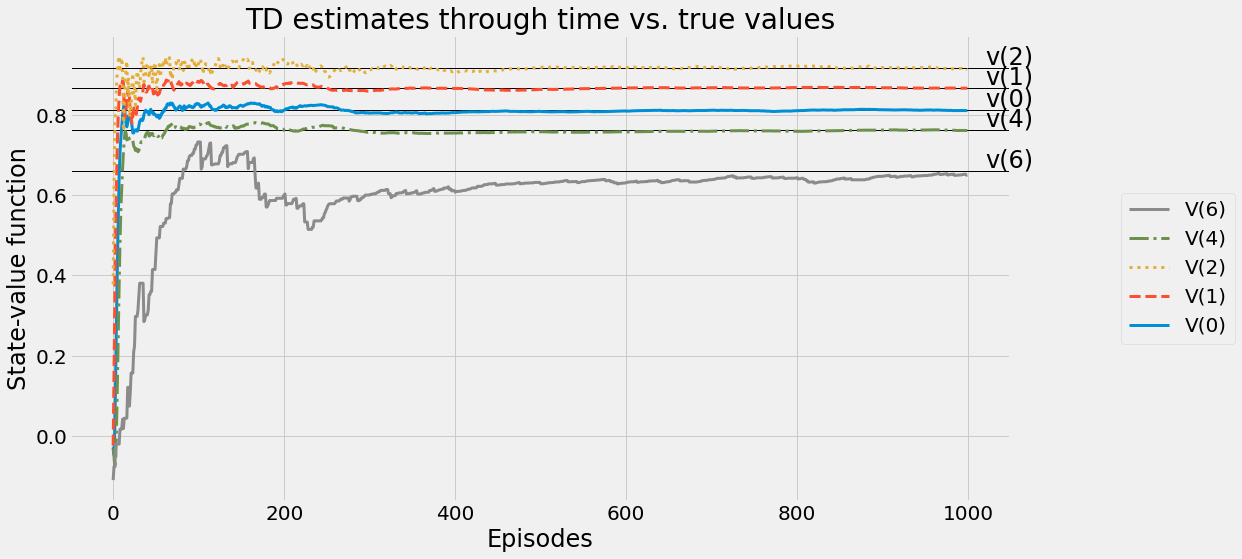
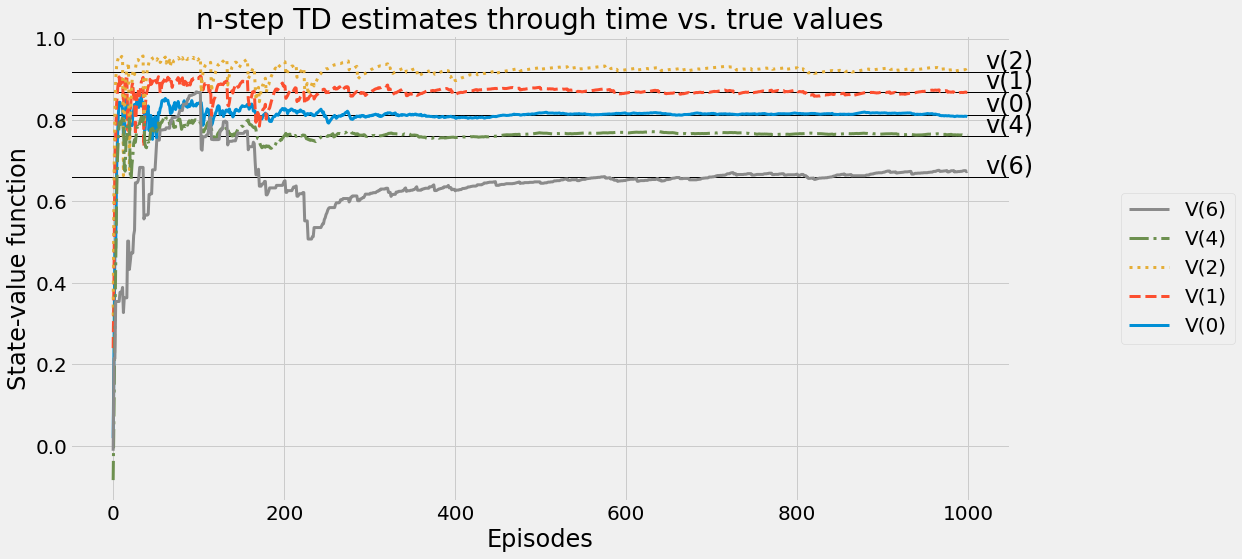
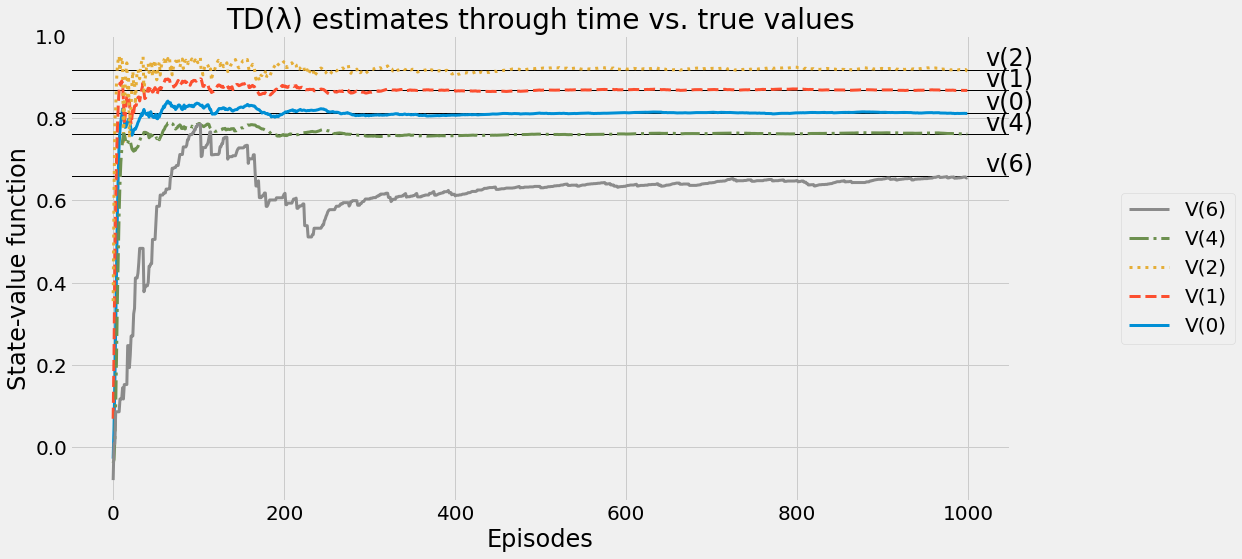
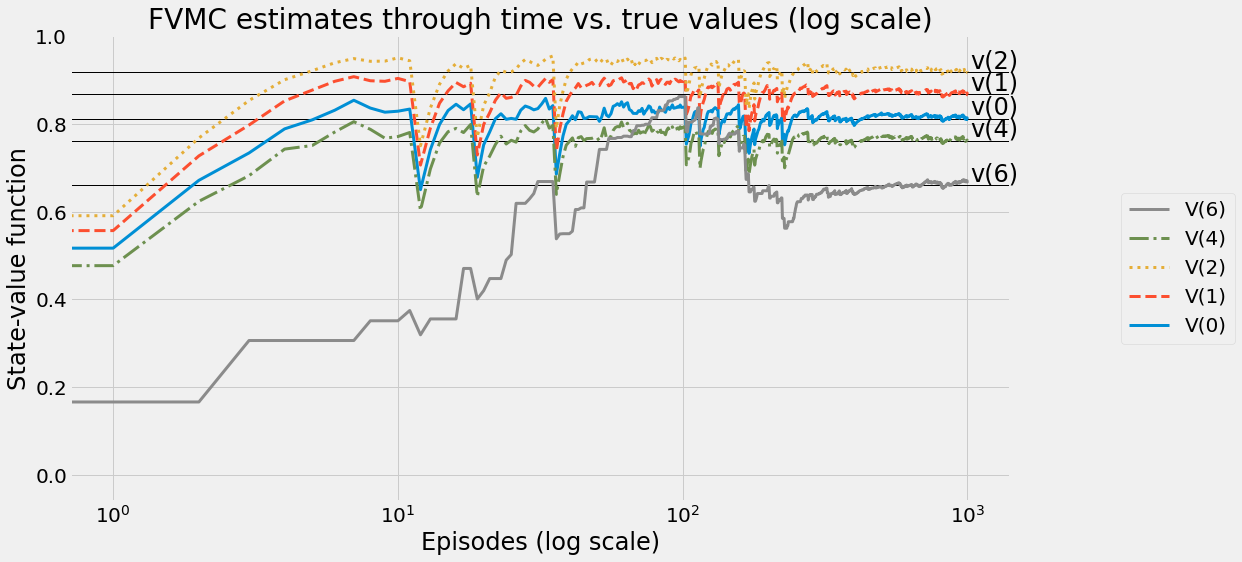
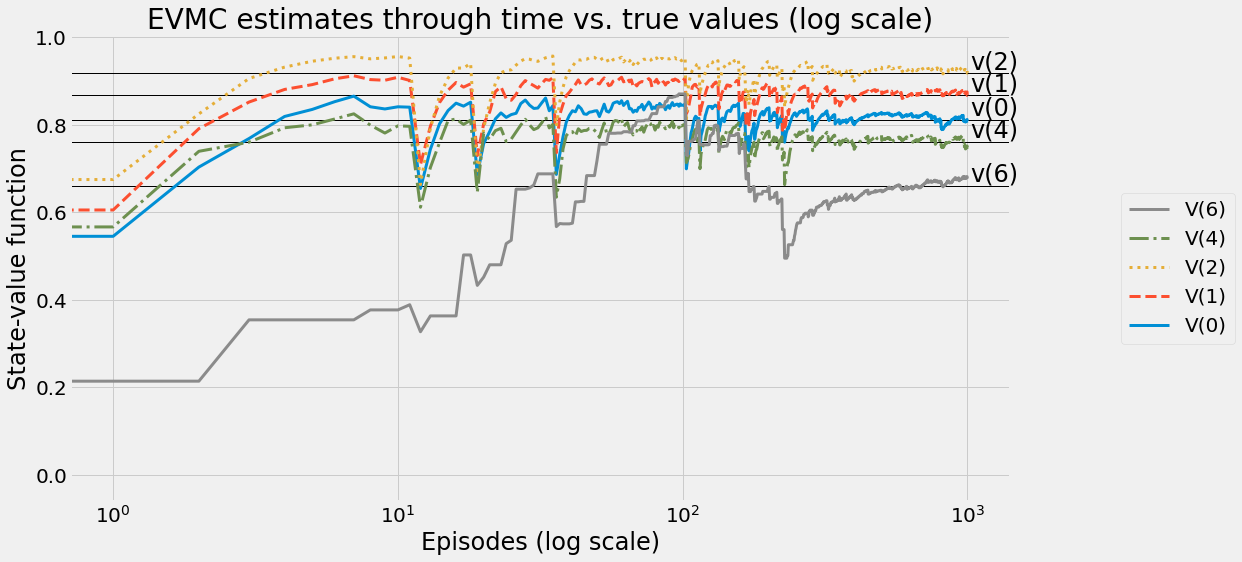
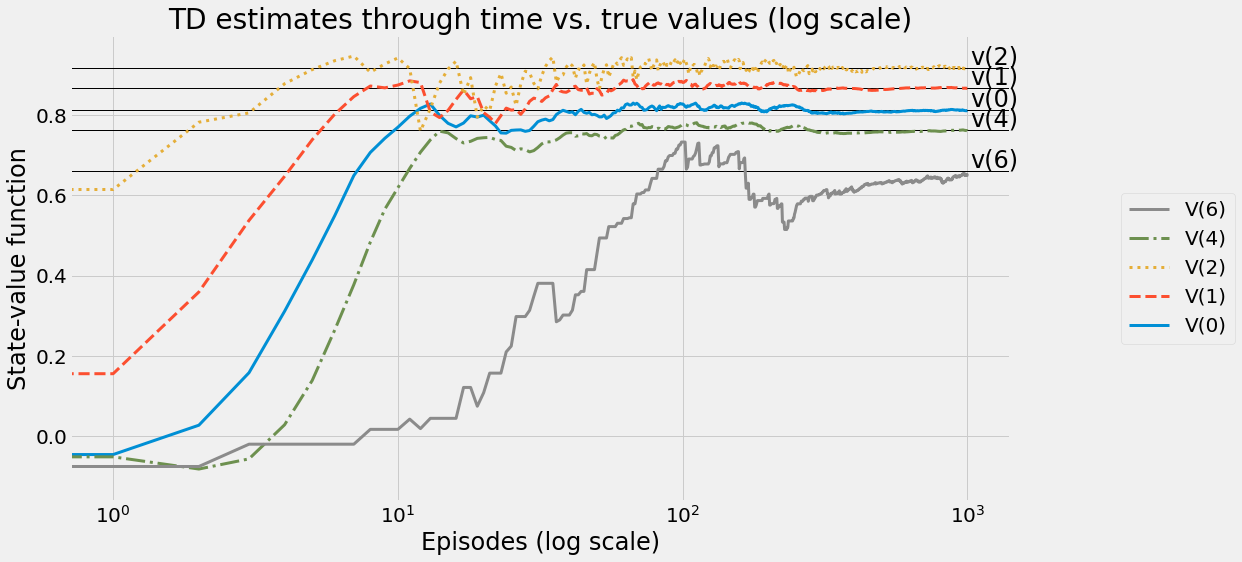
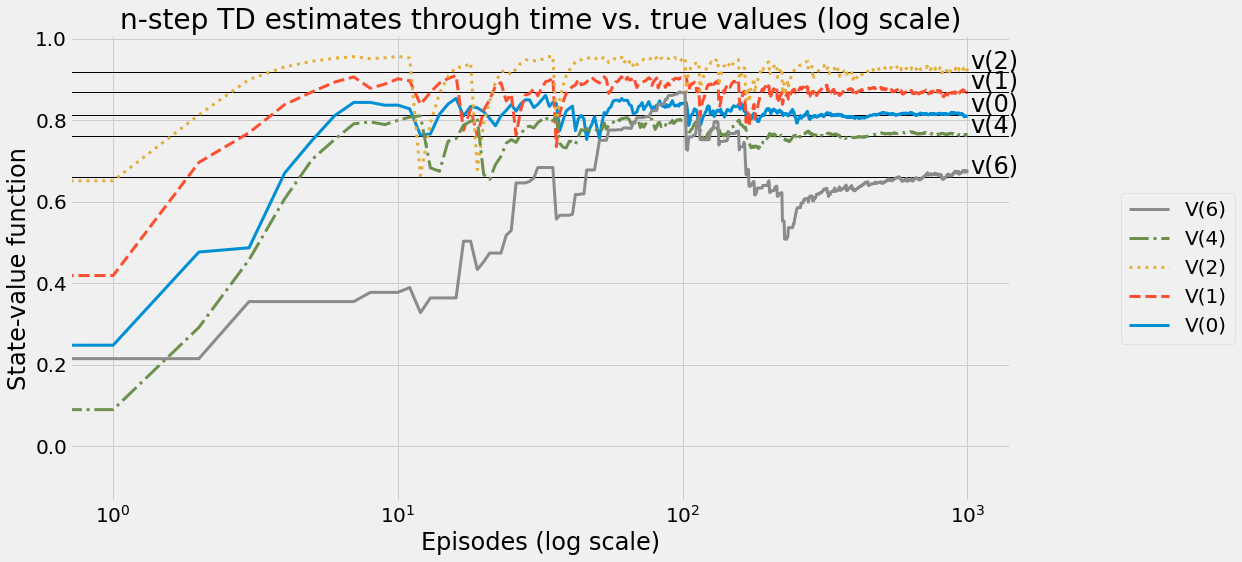
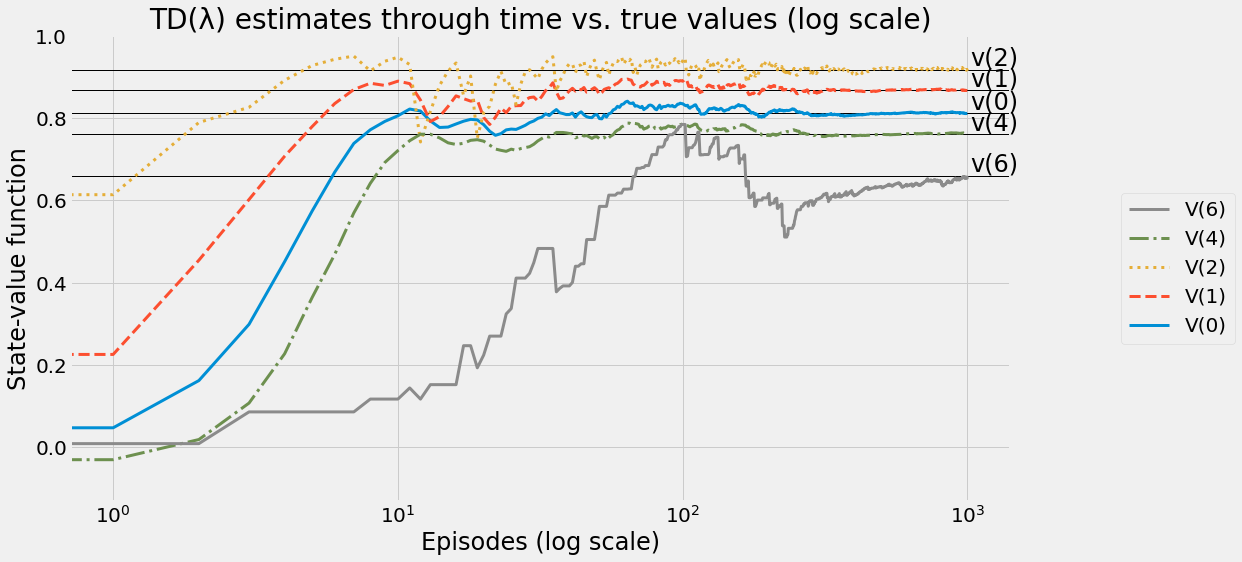
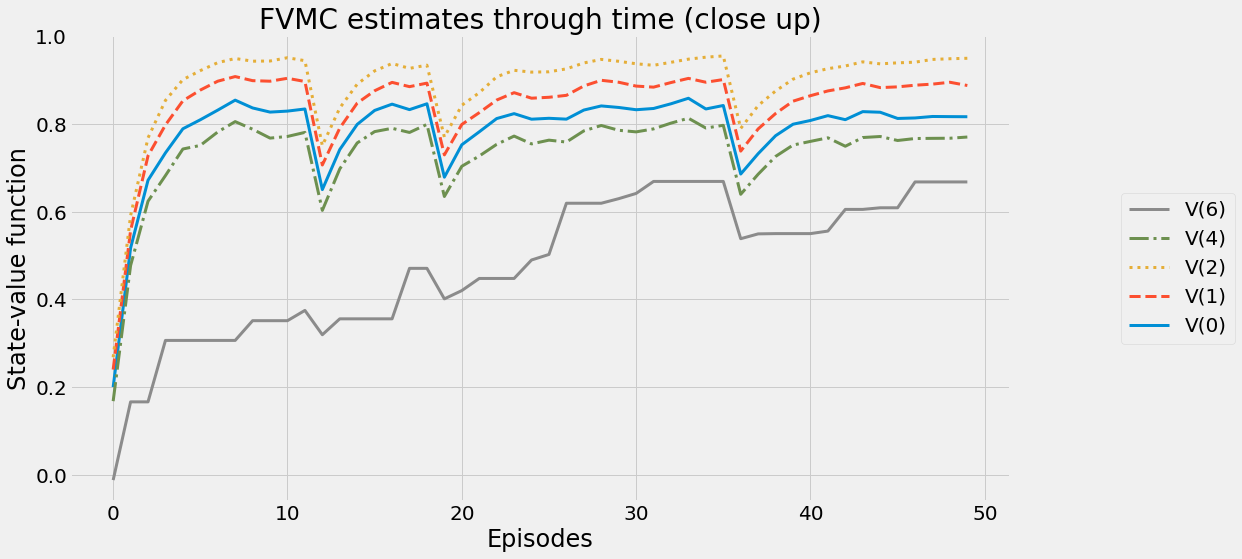
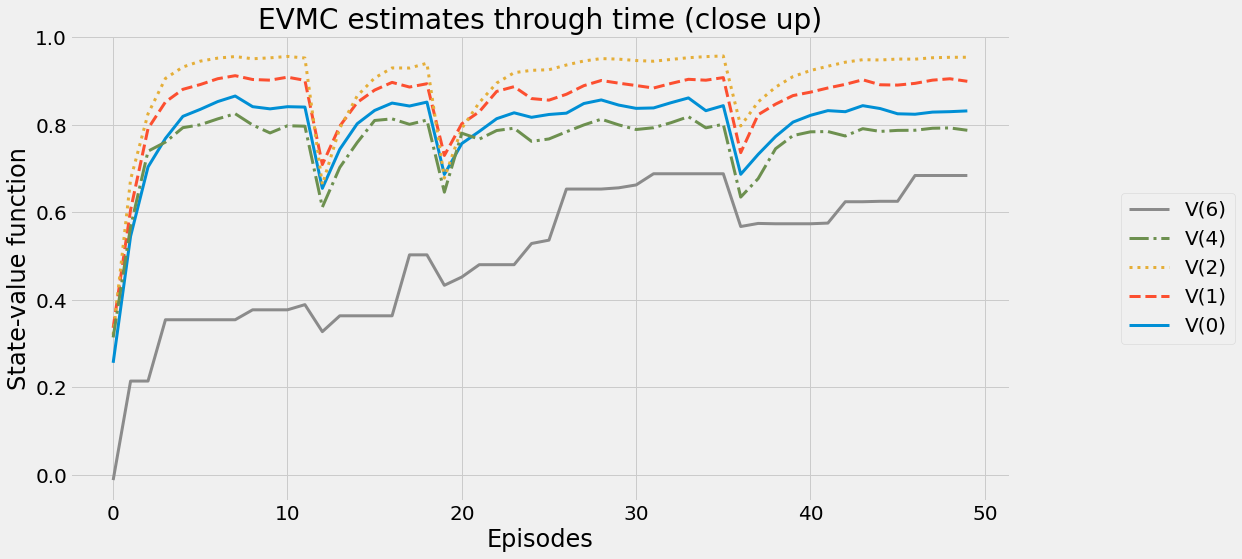
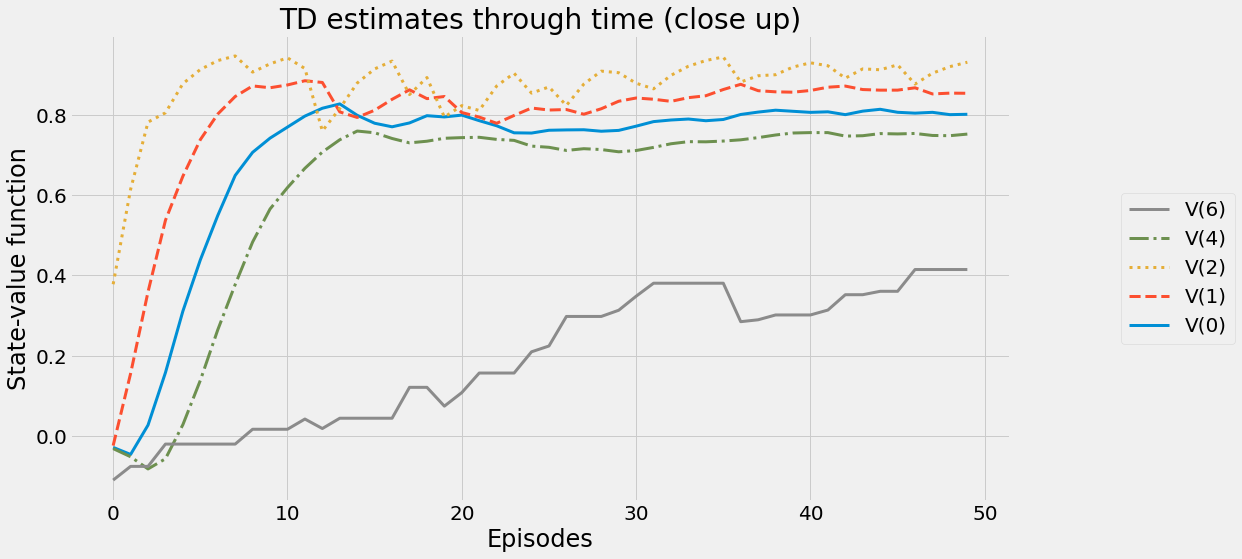
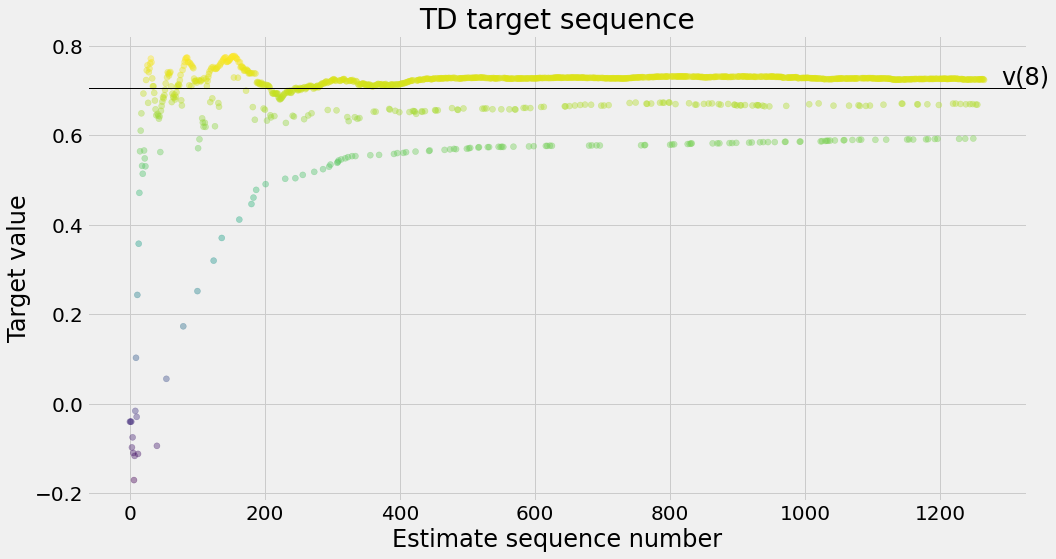
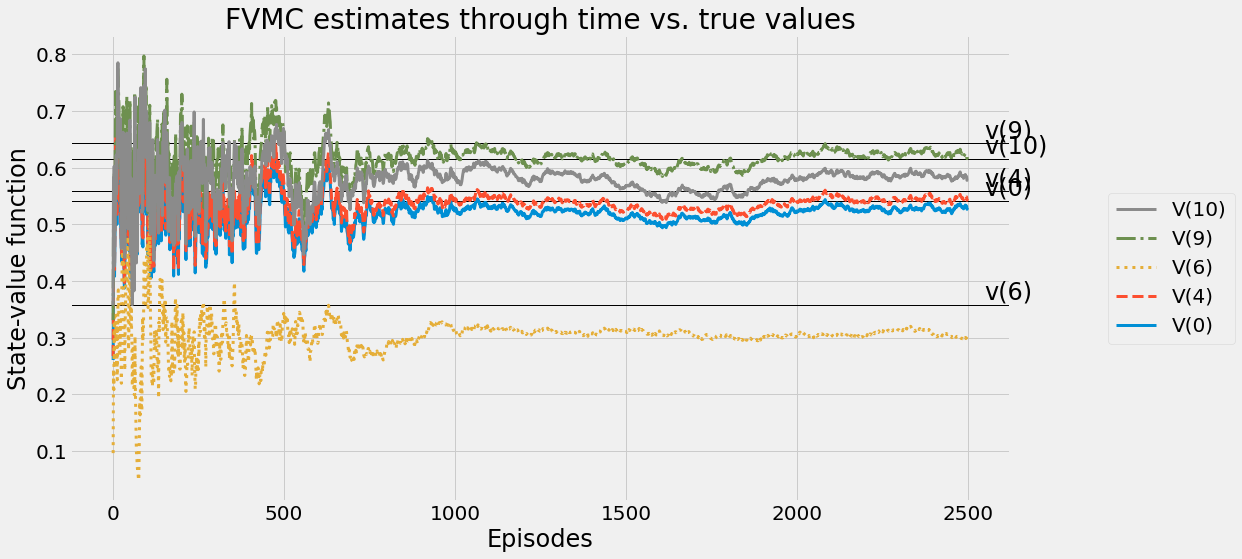
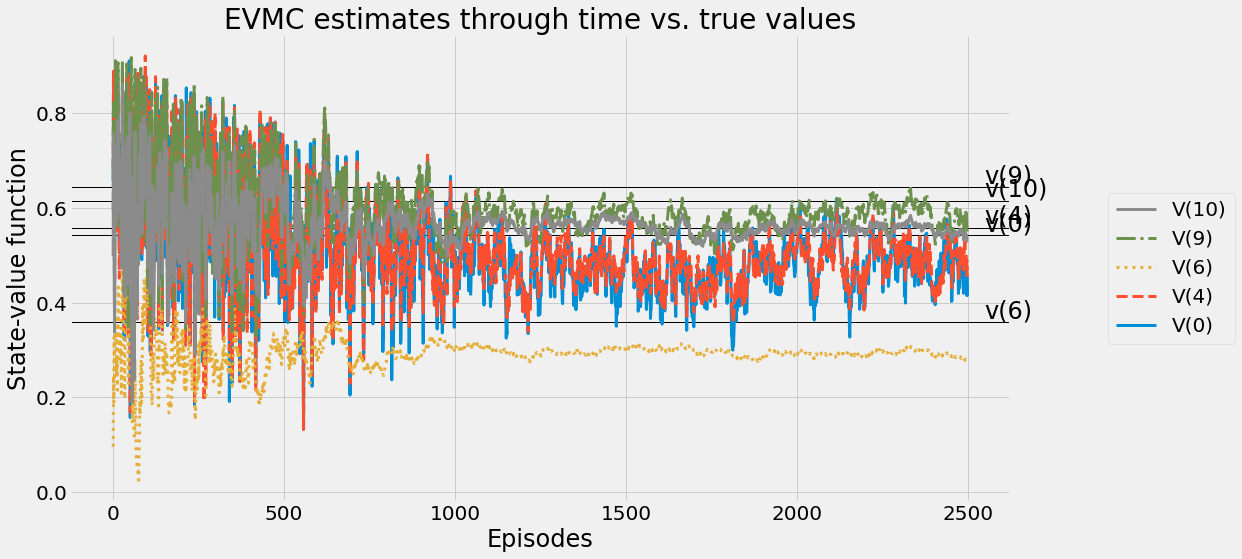
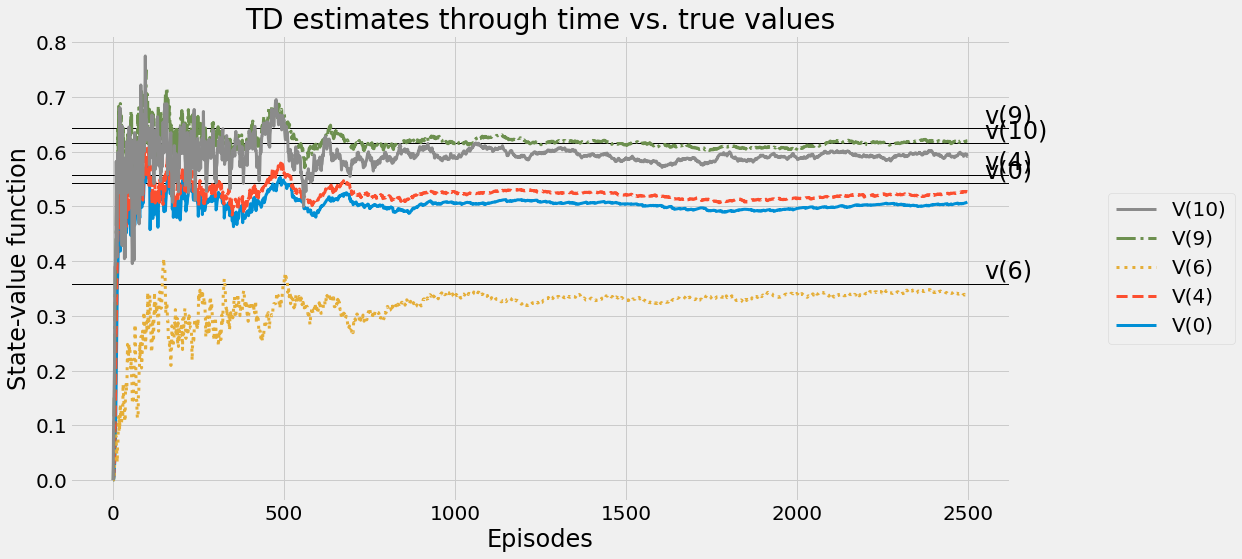
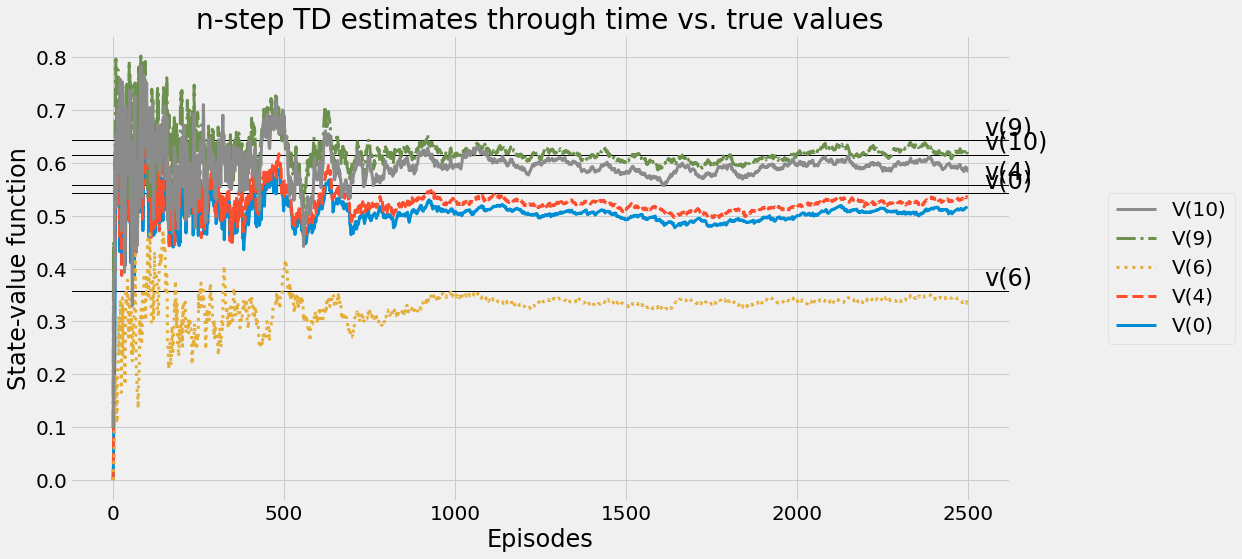
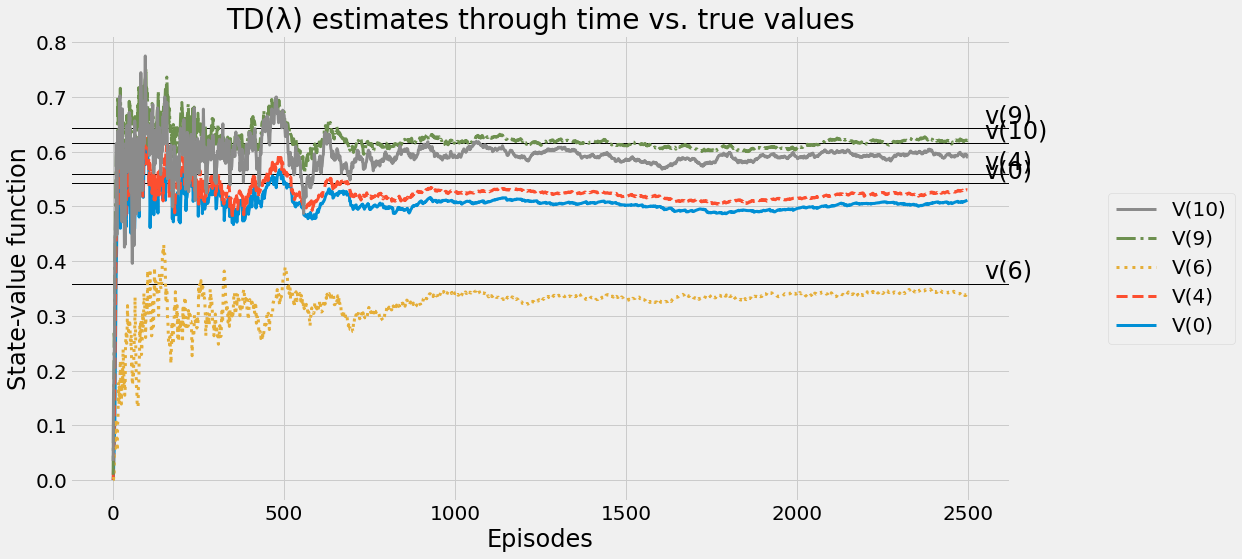
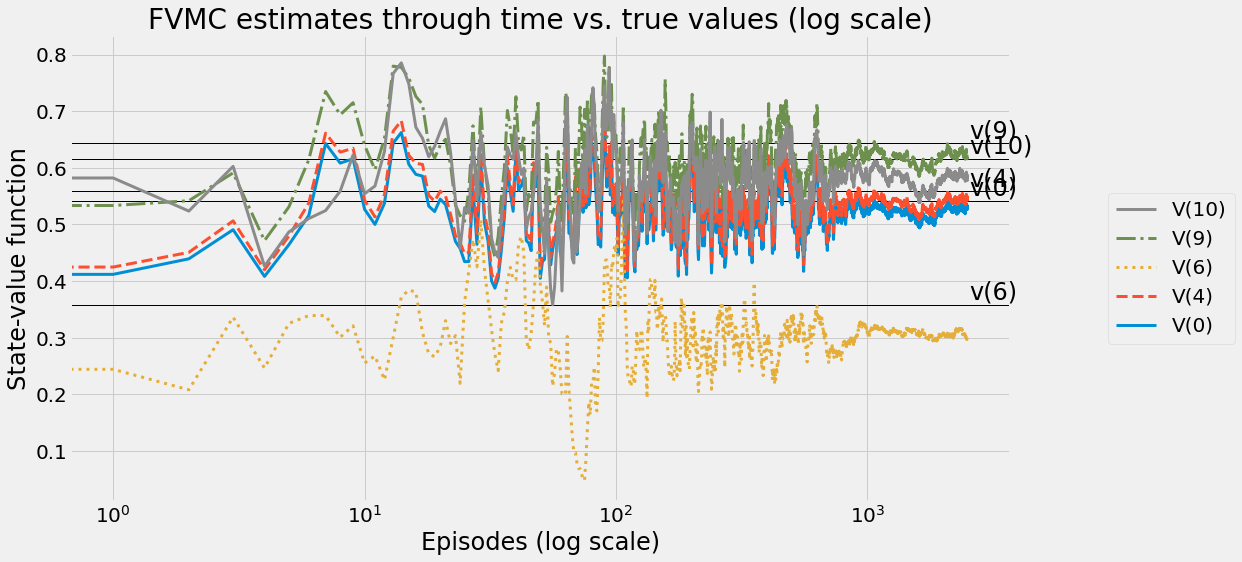
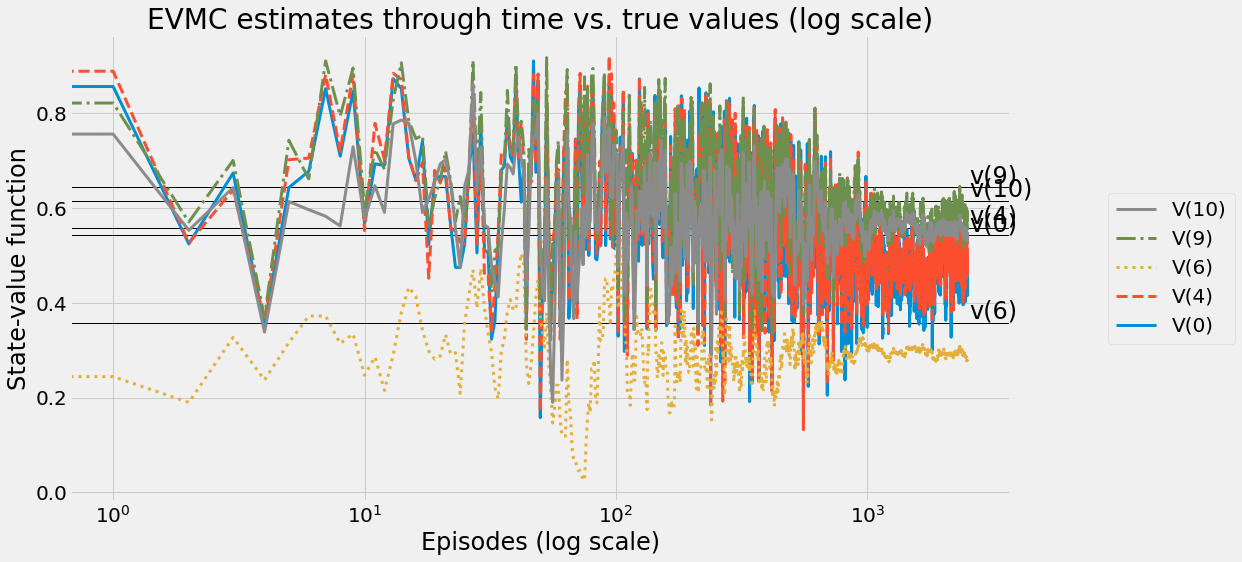
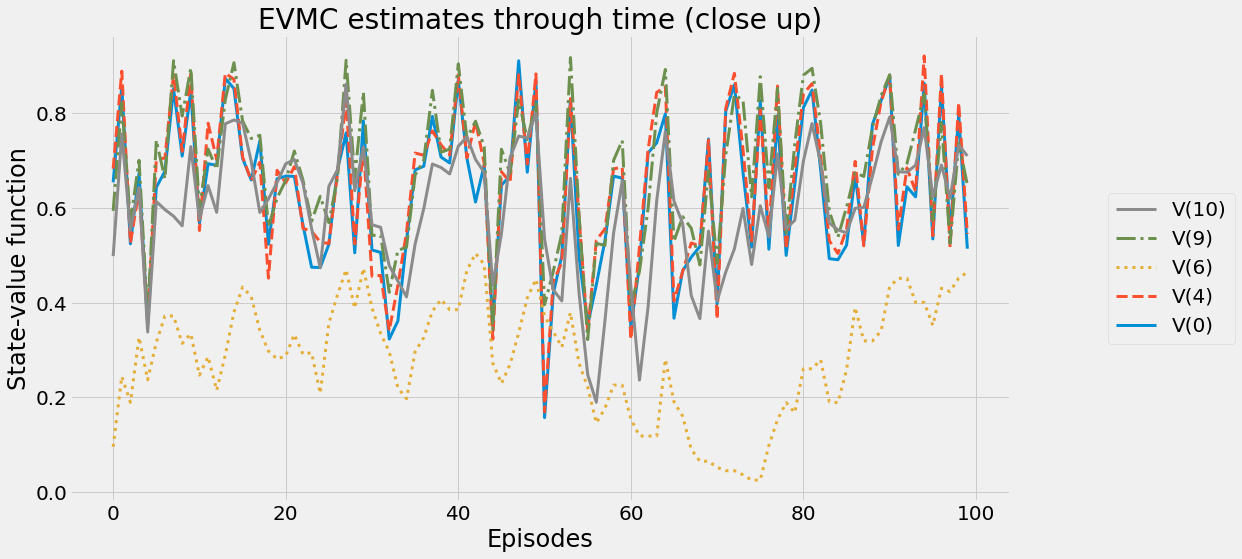
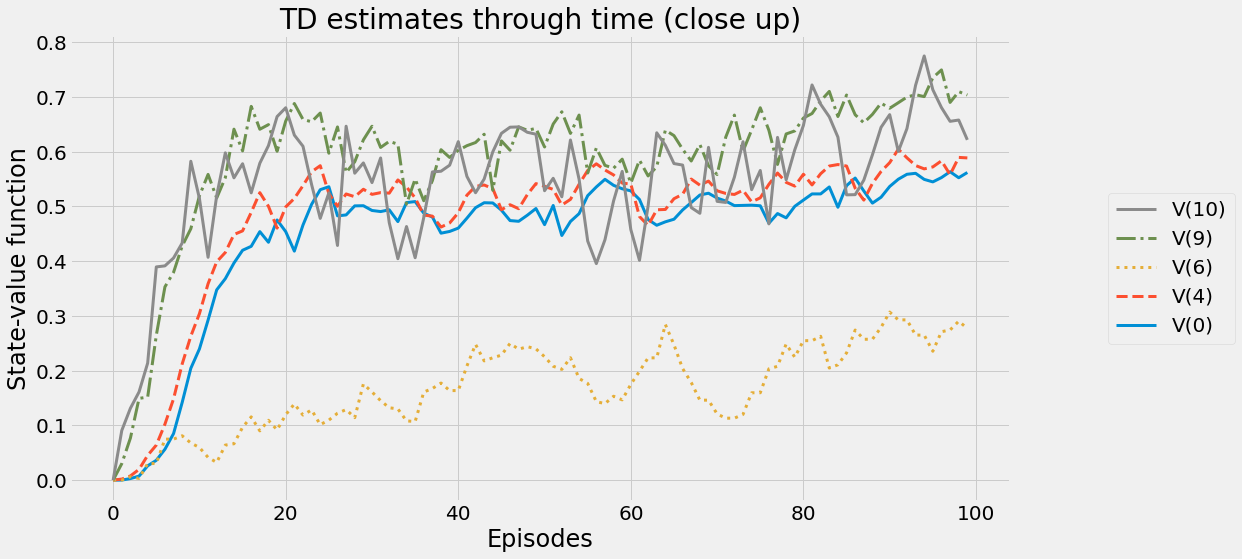
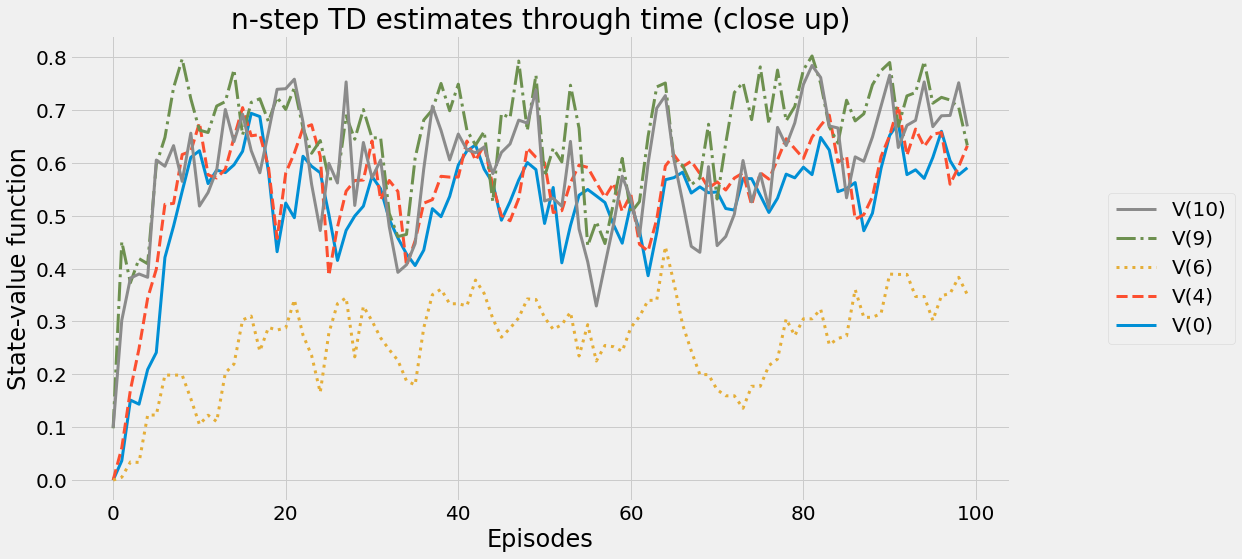
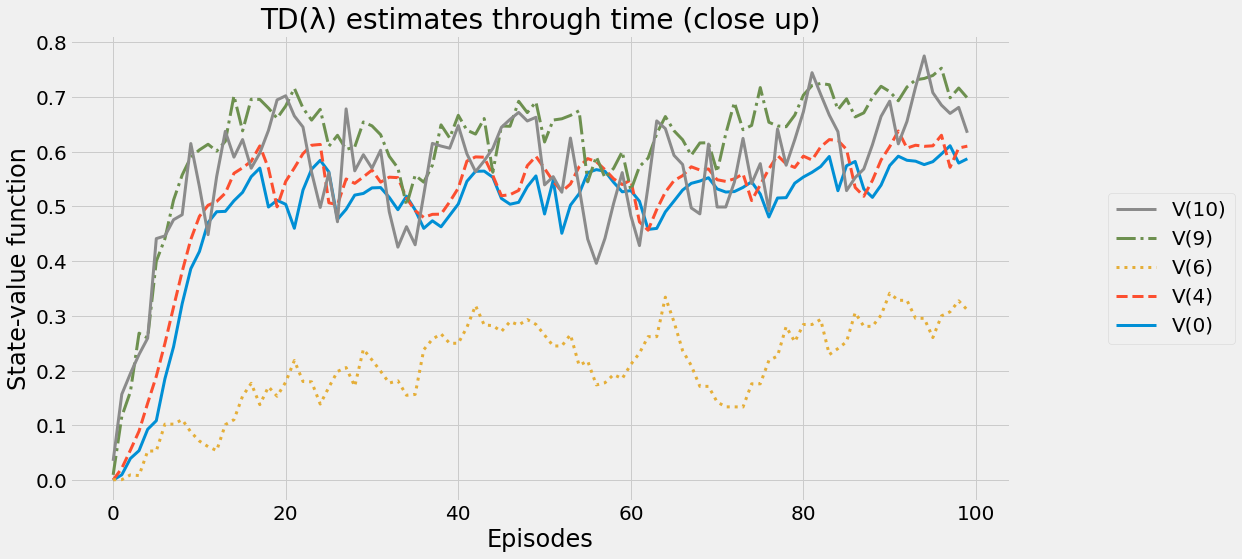
def ntd(pi,
env,
gamma=1.0,
init_alpha=0.5,
min_alpha=0.01,
alpha_decay_ratio=0.5,
n_step=3,
n_episodes=500):
nS = env.observation_space.n
V = np.zeros(nS, dtype=np.float64)
V_track = np.zeros((n_episodes, nS), dtype=np.float64)
discounts = np.logspace(0, n_step+1, num=n_step+1, base=gamma, endpoint=False)
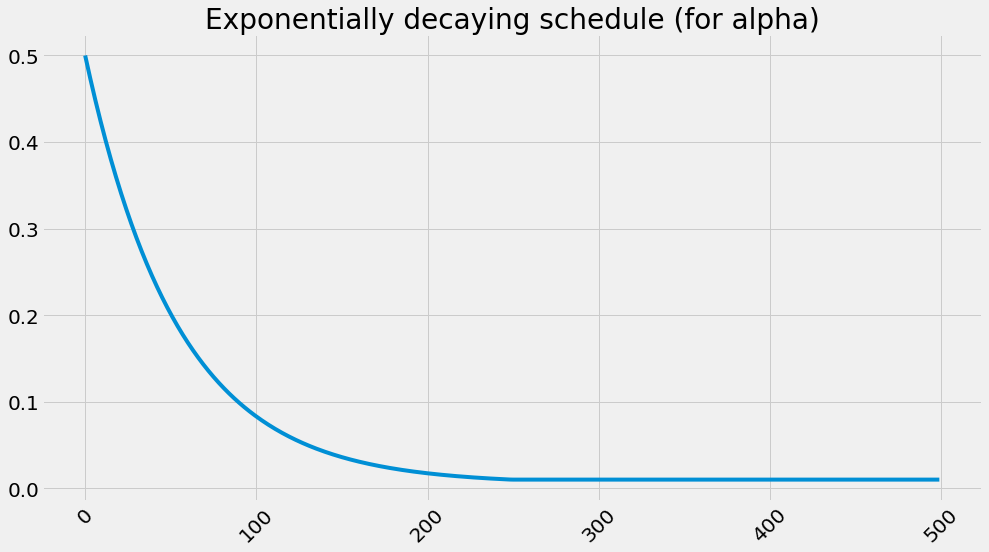
alphas = decay_schedule(
init_alpha, min_alpha,
alpha_decay_ratio, n_episodes)
for e in tqdm(range(n_episodes), leave=False):
state, done, path = env.reset(), False, []
while not done or path is not None:
path = path[1:]
while not done and len(path) < n_step:
action = pi(state)
next_state, reward, done, _ = env.step(action)
experience = (state, reward, next_state, done)
path.append(experience)
state = next_state
if done:
break
n = len(path)
est_state = path[0][0]
rewards = np.array(path)[:,1]
partial_return = discounts[:n] * rewards
bs_val = discounts[-1] * V[next_state] * (not done)
ntd_target = np.sum(np.append(partial_return, bs_val))
ntd_error = ntd_target - V[est_state]
V[est_state] = V[est_state] + alphas[e] * ntd_error
if len(path) == 1 and path[0][3]:
path = None
V_track[e] = V
return V, V_track